🌞 SQL 튜닝
지난 시간에는 Index Scan과 Index Seek의 개념과 동작 방식은 어떻게 되는지, 마지막으로 어떤 방식이 더 좋은 방식인지 알아보았다. 이번 시간에는 이전 시간에 설명하지 않고 지나친 북마크 룩업(Bookmark Lookup)이라는 개념에 대해서 알아보고, 이를 어떻게 줄일 수 있을까?에 대해서 알아보는 시간을 가져보도록 하자. 😎
마찬가지로 이번 시간에서도 저번 시간과 마찬가지로 BaseballData 데이터베이스를 사용하는 것이 아닌, Northwind 데이터베이스를 사용할 것이다.
👁️🗨️ 복습
먼저 북마크 룩업에 대해서 알아보기 전에 이전에 학습한 것을 복기해보자. 이전 시간에 인덱스 스캔과 인덱스 시크에 대해서 학습했었다. 인덱스 스캔이 일반적으로 나쁘긴 한데 예외적으로 항상 나쁜 것은 아니고, 반대로 인덱스 시크가 좋긴 하지만 또 항상 좋은것은 아니라고 했다.
그렇다면 여기서 궁금증이 생긴다. 분명 인덱스를 사용하고 있는데 왜 나쁘다는 얘기가 나오고 성능이 나빠지면서 느려지는 것일까? 바로 '북마크 룩업' 때문이다. 따라서 오늘은 이 북마크 룩업에 대해서 알아볼 것이다.
북마크 룩업에 대해서 얘기하기 전에 먼저 클러스터드 인덱스와 논클러스터드 인덱스의 차이점에 대해서 분명히 알고 가자.
-- 논클러스터드
-- 1
-- 2 3 4 5 6
-- 클러스터드
-- 1
-- 2 3 4 5 6
클러스터드는 데이터가 실제로 Leaf Page (2, 3, 4, 5, 6)에 존재하지만, 논클러스터드는 데이터를 들고 있는 것이 아니라, 데이터를 찾을 수 있는 열쇠를 들고 있는 것이다. 따라서 클러스터드 인덱스가 없을 경우 힙 테이블(Heap Table)이라는 것이 생성되는데 이는 일련의 페이지들을 아래와 같이 가지고 있다.
-- Heap Table [ {Page}, {Page} ]
이 때 논클러스터드의 Leaf Page (2, 3, 4, 5, 6)에서는 RID 라는 개념을 통해 힙 테이블에 접근하여 데이터를 찾게 된다.
위의 내용을 토대로 클러스터드의 경우 Index Seek가 발생할 경우 굉장히 좋은 현상이다. 왜냐하면 클러스터드 인덱스의 경우 데이터를 실질적으로 가지고 있기 때문에 Index Seek로 접근할 경우 굉장히 빠르게 동작하기 때문이다. 하지만 논클러스터드의 경우 위에서 얘기한바와 같이 데이터가 Leaf Page에 없다는 것이 함정이 되는거다. 따라서 데이터를 찾기 위해 추가적인 프로세스를 거쳐야 한다. 방법은 다음과 같다.
1) RID → Heap Table
2) Key → 클러스터드
위와 같이 두 가지 방법이 있는데 이 중에서 방법 1이 북마크 룩업의 개념에 해당하는 것이다. 이번 시간에는 이를 실습하도록 하자!
👁️🗨️ 북마크 룩업
늘 그렇듯이 테이블부터 새롭게 만들어주자. 오늘은 Select Into를 이용하여 테이블을 생성할 것이다.
-- TestOrders 테이블을 새로 만들어준다.
SELECT *
INTO TestOrders
FROM Orders;
-- 조회
SELECT *
FROM TestOrders;
이 후, 인덱스를 생성하고 생성된 인덱스의 번호를 조회한 뒤 해당 인덱스의 정보를 조회하도록 하자.
-- 인덱스 생성
CREATE NONCLUSTERED INDEX Orders_Index01
ON TestOrders(CustomerID);
-- 인덱스 번호 조회
SELECT index_id, name
FROM sys.indexes
WHERE object_id = object_id('TestOrders');
-- 인덱스 정보 조회
DBCC IND('Northwind', 'TestOrders', 2);

여기서는 클러스터드 인덱스를 만들어주지 않았기 때문에 힙 테이블이 분명히 존재한다. 🫡 이어서 분석을 진행해보도록 하자.
-- 각각의 개념은 얼마 걸렸는지, 페이지 논리적 접근 개수, 실제로 실행된 순서를 나타낸다
SET STATISTICS TIME ON;
SET STATISTICS IO ON;
SET STATISTICS PROFILE ON;
위 쿼리문을 작성하여 실행하여 앞으로 진행할 테스트의 시간, 논리적 접근 개수, 실제 실행 순서를 살펴보도록 하자.
먼저 첫번째다.
-- 기본 탐색
SELECT *
FROM TestOrders
WHERE CustomerID = 'QUICK';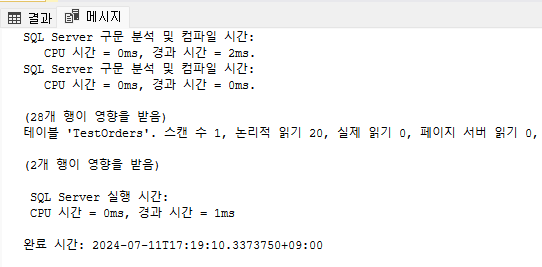
실행 후 결과 창에서 '메시지' 탭을 보면 논리적 읽기의 값이 20임을 알 수 있다. 분명히 CustomerID는 논클러스터드를 걸어놨음에도 불구하고 데이터베이스는 이를 사용하지 않고 있다. 왜 이러한 현상이 생길까? 사실 별거 없다. 단순히 데이터베이스가 그냥 테이블을 스캔하는게 더 빠르다고 판단했기 때문이다. 그렇다면 인덱스를 강제로라도 활용해서 조회할경우 어떤 결과가 나올까?
다음은 두번째다.
-- 기본 탐색 (인덱스 강제 사용)
SELECT *
FROM TestOrders WITH(INDEX(Orders_Index01))
WHERE CustomerID = 'QUICK';
마찬가지로 실행 후 메시지 탭을 보면 논리적 읽기의 값이 줄어든 것이 아니라 오히려 30으로 늘어난 것을 볼 수 있다. 이를 토대로 인덱스를 사용하는 것은 항상 최선이 아님을 명심해야한다. 그러나 갑자기 왜 30으로 늘어난 것일까? 이는 결과의 SET STATISTICS PROFILE ON; 항목을 보면 자세히 알 수 있다.

해당 쿼리는 논클러스터드의 1을 한번 순회하고, 그리고 LEAF PAGE를 한번 순회하였다. LEAF PAGE에는 데이터가 없기 때문에 LEAF PAGE에서 RID LOOKUP(=북마크 룩업)을 28번 했기 때문에 더 느려진 것을 볼 수 있다.
다음은 세번째다. 그렇다면 북마크 룩업을 줄이기 위해 노력해보자.
-- 조건 추가 (룩업을 줄이기 위한 몸부림)
SELECT *
FROM TestOrders WITH(INDEX(Orders_Index01))
WHERE CustomerID = 'QUICK' AND ShipVia = 3;

ShipVia라는 조건을 추가했기 때문에 논리적 읽기의 수는 같지만 SET STATISTICS PROFILE ON 항목의 4번 ROW에서 28개 아닌 8개의 행만 읽어들인 것을 알 수 있다.
그렇다면 북마크 룩업을 줄일 수 있는 명쾌한 해답이 있기는 한걸까?, 결론부터 얘기하면 없다. 모든것이 케이스 바이 케이스에 따라 답이 다르기 때문에 명쾌하게 해답을 내릴 수 없다. 그렇다면 여기서 포기해야 할까? 그렇지 않다. 이제 북마크 룩업을 줄이는 방법에 대해서 알아보도록 하자.
👁️🗨️ 북마크 룩업 다이어트
먼저 기존에 사용하던 인덱스 먼저 제거해주도록 하자.
-- 인덱스 삭제
DROP INDEX TestOrders.Orders_Index01;
이 후, 생각해볼수 있는 방법으로는 복합 인덱스를 통해 처리하는 방법이 있다. 인덱스를 다시 생성하지만 이번에는 ShipVia까지 조건을 추가하여 생성해주자.
-- 복합 인덱스를 통한 처리 (Covered Index)
CREATE NONCLUSTERED INDEX Orders_Index01
ON TestOrders(CustomerID, ShipVia);
이 후, 아까와 동일한 조건을 재 실행해보도록 하자.
SELECT *
FROM TestOrders WITH(INDEX(Orders_Index01))
WHERE CustomerID = 'QUICK' AND ShipVia = 3;

3번 Index Seek에서 28개를 탐색하는 것이 아닌 8개로 탐색하는 것으로 줄어든 것을 볼 수 있다. 왜 8개로 줄어든 것일까? 이유는 다음과 같다. 여태까지는 CustomerID를 통해서 조회를 했지만, 새롭게 생성한 복합 인덱스를 통해 논클러스트 Leaf Page에서 'CustomerID'만으로 조회를 하는 것이 아닌 'ShipVia'와 함께 세트로 키값을 사용했기 때문이다. 따라서 기존과 같이 힙 테이블까지 가서 데이터를 찾아야하는 것이 아닌, Leaf Page 단계에서 20개의 꽝들을 걸러낼 수 있는 것이다. 이를 커버 인덱스(Covered Index)라고 한다.
그렇다면 '오잉? 그러면 앞으로 '조건1' AND '조건 2'가 필요할 경우 무조건 Index를 조건 1, 조건 2를 넣어서 Covered Index를 통해 처리하면 장땡 아닌가?' 생각할 수 있겠지만 데이터베이스가 그렇게 간단하지가 않다. 이런식으로 복합 인덱스를 통해 데이터를 조회할 경우엔 빠르지만 그 외 DML(Insert, Update, Delete)의 작업을 처리할 때 작업 부하가 증가한다. 따라서 데이터의 갱신이 잦지 않다면 상관 없지만 갱신되는게 매우 활발하다면 이 방법이 정답이 아니다.
그렇다면 또 무슨 방법을 통해서 처리해야할까? 바로 Include를 통해 처리하는 방법이다. 이전과 같이 기존에 사용하던 인덱스는 삭제하도록 하자.
-- 인덱스 삭제
DROP INDEX TestOrders.Orders_Index01;
이번에는 복합 인덱스가 아닌 'INCLUDE'를 통해 인덱스를 생성해 줄것이다.
-- 룩업을 줄이기 위한 몸부림 2
CREATE NONCLUSTERED INDEX Orders_Index01
ON TestOrders(CustomerID) INCLUDE (ShipVia);
복합 인덱스가 아닌 INCLUDE를 사용하면 뭐가 다를까? 위 쿼리문의 뜻은 'CustomerID를 통해 정렬은 하겠지만, ShipVia에 대한 정보는 힌트와 같이 추가로 들고있겠다.' 라는 뜻이 된다. 따라서 논클러스터드의 구조는 다음과 같이 변경된다.
-- 논클러스터드
-- 1
-- 2[28(data1(ShipVia=3), data2(ShipVia=2), ... data28] 3 4 5 6
그러면 이렇게 할 경우 무슨 장점이 있을까? 기존의 28개의 데이터를 찾았을 때 문제가 되었던 것이 뭐냐면 ShipVia의 값이 3번인 애들은 논클러스트 Leaf Page 2에서 알 수 없었기 때문에 힙 테이블까지 데이터를 들고가서 찾아야 했는데, 위와 같이 Include를 사용 할 경우 정보를 추가로 들고있기 때문에 Leaf Page 2에서 ShipVia 조건을 걸러낸 다음 찾기 때문에 실질적으로 필요한 정보만 힙 테이블에서 찾을 수 있게 된다.
-- 다시 조회해보자!
SELECT *
FROM TestOrders WITH(INDEX(Orders_Index01))
WHERE CustomerID = 'QUICK' AND ShipVia = 3;
북마크 룩업을 줄이기 위해 두 조건에 대해서 알아보았다. 그럼에도 불구하고 답이 없다고 느껴질 경우 제 3의 옵션인 클러스터드 인덱스를 활용해서 고려할 수 있다. 그렇지만 이 또한 치명적인 단점이 존재하는데 클러스터드 인덱스는 테이블당 1개만 사용할 수 있다는 것이다.
👁️🗨️ 결론
논클러스터드 인덱스가 악영향을 주는 경우가 무엇이 있을까?
→ 북마크 룩업이 심각한 부하를 야기할 때!
이에 대한 대안은 무엇일까?
옵션 1) Coverd Index (검색할 모든 컬럼을 포함하겠다)
옵션 2) Index에다가 Include로 힌트를 남긴다.
옵션 3) 클러스터드를 고려한다. 단 1번만 사용할 수 있는 인덱스가 한계가 있으며 아울러 논클러스터드 인덱스에게 까지도 영향을 준다.
'공부 > 인프런 - Rookiss' 카테고리의 다른 글
| Part 5-3-7. SQL 튜닝 : Nested Loop 조인 (0) | 2024.07.15 |
|---|---|
| Part 5-3-6. SQL 튜닝 : 인덱스 컬럼 순서 (1) | 2024.07.12 |
| Part 5-3-4. SQL 튜닝 : Index Scan vs Index Seek (1) | 2024.07.10 |
| Part 5-3-3. SQL 튜닝 : Clustered vs NonClustered (1) | 2024.06.15 |
| Part 5-3-2. SQL 튜닝 : 복합 인덱스, 조회/SPLIT/가공 테스트 (1) | 2024.06.05 |