🌞 SQL 튜닝
지난 시간에는 복합 인덱스를 사용 할 때 인덱스의 컬럼 순서를 어떻게 설정하냐에 따라 논리적 읽기의 값이 변하는 것에 대해서 알아보았다. 이번 시간에는 조인의 3가지 원리 중 하나인 Nested Loop(이하 NL 조인이라 한다.)에 대해서 알아보는 시간을 가져보도록 하자.
이번 시간에서는 이제 Northwind 데이터베이스를 사용하는 것이 아닌, BaseballData 데이터베이스로 돌아와 사용한다.
🐕🦺 조인의 원리
조인은 데이터베이스에서 굉장히 중요한 개념이다. 애당초 우리가 RDBMS를 사용할 경우 데이터는 모두 여러 테이블에서 가져와서 사용하기 때문이다. 예를 들어 MMORPG만 하더라도 플레이어 정보, 몬스터 정보, 아이템 정보 등 여러 정보를 담당하고 있는 데이터베이스가 각각의 독립적인 개념으로 존재할 것이기 때문이다. 따라서 우리는 테이블에 있는 내용을 조립해 데이터를 추출해서 사용해야 하기 때문에 조인은 굉장히 중요한 개념이다.
조인이 중요하다는 것은 알겠지만, 조인은 크게 아래와 같이 세 가지 방법으로 이루어져있다.
-- 조인 원리
-- 1) Nested Loop (NL) 조인
-- 2) Merge(병합) 조인
-- 3) Hash(해시) 조인
각각의 장단점을 알아보기 위해 3개의 조인을 모두 사용해보고, 그 중에서 오늘은 NL 조인에 대해서 학습하도록 하자.
-- INNER JOIN을 통한 데이터 조회
SELECT *
FROM players AS p
INNER JOIN salaries AS s
ON p.playerID = s.playerID;
-- Merge Join을 통해서 결과 값을 보여준다.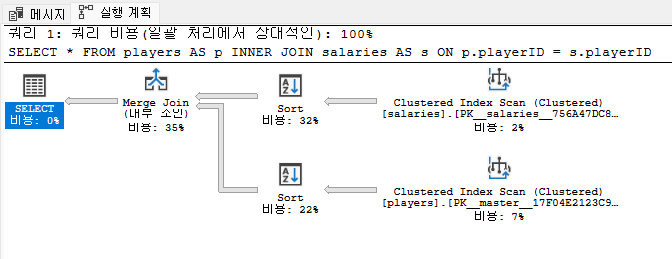
이번에는 NL이 나오도록 쿼리를 작성해보자.
SELECT TOP 5 *
FROM players AS p
INNER JOIN salaries AS s
ON p.playerID = s.playerID;
-- Nested Loop를 통해서 결과 값을 보여준다.
마지막으로 Hash 조인이 나타나도록 쿼리를 작성해보자.
SELECT *
FROM salaries AS s
INNER JOIN teams AS t
ON s.teamID = t.teamID;
-- Hash를 통해서 결과 값을 보여준다.
위의 실행결과를 바탕으로 조인은 크게 3가지의 형태가 있다는 것을 알았다. 그러나 우리는 여태 클러스터드, 논클러스트 Index Scan, Index Seek만 알고 있었는데 Merge, NL, Hash 조인의 개념이 나타나니 이것이 무엇을 나타내는지 명확하게 알 수 없다. 따라서 오늘은 이 중에서 NL 조인에 대해서 알아보도록 하자.
물론 경우에 따라서 우리는 데이터베이스에게 옵션(=힌트)를 설정해 특정 조인을 사용하도록 유도 할 수 있다. 아래는 내부 조인(NL 조인)을 옵션으로 설정하여 강제한 내용이다.
SELECT *
FROM players AS p
INNER JOIN salaries AS s
ON p.playerID = s.playerID
OPTION(LOOP JOIN);
-- 옵션을 통해 강제로 특정 조인을 사용할 수 있도록 할 수 있다.
🐕🦺 Nested Loop 조인 - C#
NL 조인에 대해서 보다 쉽게 이해하기 위해 오늘은 C# 코드를 통해 작업을 진행하도록 하자. 간단하게 콘솔 프로젝트를 생성해서 아래와 같이 작성하자.
class Player
{
public int playerId;
// ...
}
class Salary
{
public int playerId;
// ...
}
먼저 플레이어 클래스와 샐러리 클래스가 있는데 둘 다 playerID라는 정보를 들고 있다고 가정하자. 이 후 두개의 리스트를 만들고 랜덤을 통해 1/2확률로 리스트에 플레이어 아이디를 넣어주자. 코드는 아래와 같다.
Random rand = new Random();
List<Player> players = new List<Player>();
for (int i = 0; i < 1000; i++)
{
if (rand.Next(0, 2) == 0)
continue;
players.Add(new Player() { playerId = i });
}
List<Salary> Lsalaries = new List<Salary>();
for (int i = 0; i < 1000; i++)
{
if (rand.Next(0, 2) == 0)
continue;
Lsalaries.Add(new Salary() { playerId = i });
}
그렇다면 이 상황에서 퀴즈를 풀어보자. 만약 players에도 있고, salaries에 있는 정보를 추출한다고 한다면 어떻게 해야할까? 대부분의 사람들은 이중 포문을 통해 문제를 해결하려고 할 것이다.
// Nested Loop
// Nested(내포하는) Loop(루프)
List<int> result = new List<int>();
foreach (Player p in players)
{
foreach (Salary s in Lsalaries)
{
if (p.playerId == s.playerId)
{
result.Add(p.playerId);
break;
}
}
}
위와 같이 이중 포문을 돌면서 처리를 할 것일텐데, 이것이 바로 NL 조인의 개념이다. 즉 중첩된 루프라는 것이다. 따라서 NL 방식에서 데이터를 하나하나씩 돌면서 찾는 것이 NL의 핵심이다. 그렇지만 이중포문으로 인해 시간 복잡도는 O(N^2)가 되기 떄문에 굉장히 느리다. 따라서 이를 개선하는 방법으로 List가 아닌 Dictionary를 사용하는 방법이 있다.
// 어떻게 개선을 하면 좋을까?
// 리스트가 아닌 Dictionary를 사용하면 어떨까?
// 시간 복잡도 : O(N)
// 개선된 NL
foreach (Player p in players)
{
Salary s = null;
if (Dsalaries.TryGetValue(p.playerId, out s))
{
result.Add(p.playerId);
}
}
Dictionary를 사용할 경우 해시를 사용하기 떄문에 시간 복잡도는 O(N^2)에서 O(N)으로 변경된다. 그렇다면 NL을 어떤 상황에서 사용하는 것이 가장 유리할까? 바로 제한된 개수를 찾아야 할 때 가장 빠르기 때문에 유리하다. 아래 코드를 살펴보자.
// NL을 사용할 때 유리한 경우가 무엇이 있을까?
// result를 그냥 아무거나 최대 5개만 찾아줘
foreach (Player p in players)
{
Salary s = null;
if (Dsalaries.TryGetValue(p.playerId, out s))
{
result.Add(p.playerId);
if (result.Count >= 5)
break;
}
}
만약 players의 데이터가 천만개가 되어도 우리는 데이터를 찾는 순간 바로 빠져나오기 때문에 매우 빠르게 처리할 수 있다. 따라서 집합이 2개가 있을 경우 이중 포문의 외부에서 내부를 하나하나씩 서칭하는 것이 NL의 개념이며, 내부에 있는 집합을 특정 개수만큼 찾을 경우 성능이 훨씬 더 좋아지는 것을 알 수 있다. 이제 다시 SQL로 돌아가자.
🐕🦺 Nested Loop 조인 - SQL
SQL로 돌아오면 아까보다는 이해가 조금 더 쉽게 될 것이다. 이제 아까 실행했던 쿼리문을 다시 실행해서 분석해보자.
SELECT *
FROM players AS p
INNER JOIN salaries AS s
ON p.playerID = s.playerID
OPTION(LOOP JOIN);
실행계획을 살펴보면 Index Seek가 뜬 것을 알 수 있다. 이는 리스트 형태가 아닌 Dictionary 형태로 내부를 실행했다는 것을 의미한다. 이 후 가운데에서 Key Lookup과 중첩 루프를 한 것을 볼 수 있는데 이는 논클러스트이기 떄문에 클러스트에 키 값을 바탕으로 조회를 하기 위해 사용한 것을 알 수 있다.
또한 Inner Join을 통해 salary를 사용했지만, 실행계획을 보면 player가 먼저 온 것이 아니라 salary로 되어 있으며, 내부가 player가 된 걸 볼 수 있다. 이러한 경우에도 옵션을 통해 강제로 설정할 수 있다.
-- 옵션을 설정해 강제로 실행계획을 변경한다.
SELECT *
FROM players AS p
INNER JOIN salaries AS s
ON p.playerID = s.playerID
OPTION(FORCE ORDER, LOOP JOIN);
실행계획을 살펴보면 이전과 다른 클러스터드와 클러스터드가 뜬 걸 볼 수 있다. 즉 이는 우리가 C#에서 리스트와 리스트를 쓴것과 일하다고 볼 수 있다.
마지막으로, 그렇다면 아까는 어떻게 NL이 실행 계획으로 나타났을까?
SELECT TOP 5 *
FROM players AS p
INNER JOIN salaries AS s
ON p.playerID = s.playerID;
정답은 바로 TOP 5에 있다. 이는 최종 결과물이 고정되어 있는 경우 NL 전략이 굉장히 우수하게 작동하는 것과 동일한 것이다. 즉 C#에서 사용한 Count >= 5와 동일한 로직의 맥락인 셈이다.
🐕🦺 결론
NL 특징으로는 먼저 액세스 한 (OUTER) 테이블의 로우를 차례 차례 스캔을 하면서 Inner 테이블에 랜덤 엑세스 한다. 그렇지만 INNER 테이블에 인덱스가 없을 경우 답이 없다! 마지막으로, 부분 범위 처리에 효과적이다. (ex. TOP 5)
'공부 > 인프런 - Rookiss' 카테고리의 다른 글
| Part 5-3-9. SQL 튜닝 : Hash 조인 (0) | 2024.07.17 |
|---|---|
| Part 5-3-8. SQL 튜닝 : Merge 조인 (0) | 2024.07.16 |
| Part 5-3-6. SQL 튜닝 : 인덱스 컬럼 순서 (1) | 2024.07.12 |
| Part 5-3-5. SQL 튜닝 : 북마크 룩업 (0) | 2024.07.11 |
| Part 5-3-4. SQL 튜닝 : Index Scan vs Index Seek (1) | 2024.07.10 |