🌞 SQL 튜닝
지난 시간에는 인덱스 분석을 통해 인덱스를 생성하고, 생성한 인덱스의 값과 인덱스 내부에 테이블 값에 대해서 알아보았다. 이번 시간에는 복합 인덱스를 통해 여러 칼럼을 동시에 인덱스를 걸어서 조회해보고, 여러 칼럼을 동시에 조회했을 때 특정 칼럼만 조회할 경우 어떤일이 발생하는지 등에 대해 알아보는 시간을 가져보도록 하자. 😋
단, 이번 시간에서도 저번 시간과 마찬가지로 BaseballData 데이터베이스를 사용하는 것이 아닌, Northwind 데이터베이스를 사용할 것이다. 😎
🔶 복합 인덱스
복합 인덱스라고 하니 조금 어려워보이지만 사실 복합 인덱스는 인덱스를 걸 때 여러 컬럼을 동시에 인덱스를 걸어버리는 것이 복합 인덱스이다. 늘 그렇듯이 말로 설명하면 어려우니 예제를 통해서 알아보는 시간을 가지자. 다음 예제는 주문 상세 정보를 살펴보는 예제이다.
-- 주문 상세 정보를 살펴보자
SELECT *
FROM [Order Details]
ORDER BY OrderID;
-- 이전 시간과 달리, CREATE INTEX를 명령어를 사용하지 않고
-- INTO 명령어를 통해 임시 테스트 테이블을 만들고 데이터를 복사한다.
SELECT *
INTO TestOrderDetails
FROM [Order Details];
-- 조회
SELECT *
FROM TestOrderDetails;
테이블을 생성해 주었으니 이제 복합 인덱스를 추가해보자.
-- 복합 인덱스 추가
CREATE INDEX Index_TestOrderDetails
ON TestOrderDetails(OrderID, ProductID);
-- OrderID와 ProductID를 세트로 묶어서 인덱스 생성
-- 생성한 인덱스 정보 살펴보기
EXEC sp_helpindex 'TestOrderDetails';

인덱스를 생성해주었으니, 이제 인덱스의 적용 방식을 알아보기 위해서 다양한 방법으로 테이블을 조회해보자.
-- 총 4가지 방법으로 조회한다.
-- OrderID, ProductID로 조회할 때,
-- ProductID, OrderID로 조회할 때,
-- OrderID 조회할 때,
-- ProductID 조회할 때,
-- 인덱스 적용 테스트 1 > GOOD
SELECT *
FROM TestOrderDetails
WHERE OrderID = 10248 AND ProductID = 11;
-- 인덱스 적용 테스트 2 > GOOD
SELECT *
FROM TestOrderDetails
WHERE ProductID = 11 AND OrderID = 10248;
-- 인덱스 적용 테스트 3 > GOOD
SELECT *
FROM TestOrderDetails
WHERE OrderID = 10248;
-- 인덱스 적용 테스트 4 > BAD
SELECT *
FROM TestOrderDetails
WHERE ProductID = 11;


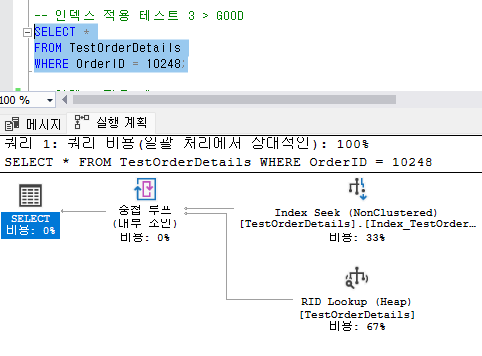

각 쿼리문 실행 후 실행 계획을 조회할 경우 테스트 1~3의 경우 설정한 인덱스를 통해 조회를 정상적으로 해주고 있으므로 Index Seek을 통해 실행 계획의 값이 나오지만, 테스트 4의 경우 인덱스를 활용하지 못하고 Table Scan의 값을 나타내는 것을 볼 수 있다. 즉, Index Seek는 인덱스를 정상적으로 활용이 되어 좋은 상태이며, Index Scan은 테이블을 정상적으로 활용하지 못해 테이블을 전체 스캔하고 있으므로 나쁜 상태를 나타낸다.
왜 ProductID로 조회할 경우 테이블 스캔으로 처리할까? 이를 알아보기 위해 인덱스 정보를 살펴보도록 하자.
-- 인덱스 정보를 살펴보자
DBCC IND('Northwind', 'TestOrderDetails', 2);
-- PagePID는 사람마다 모두 다르므로 감안하자!
-- IndexLevel 및 PagePID에 따른 인덱스 정보 상태는 다음과 같다.
-- 992
-- 936 960 961 962 963 964
-- 나는 936이 제일 앞에 있으므로 해당 테이블을 조회하였다.
DBCC PAGE('Northwind', 1, 936, 3);
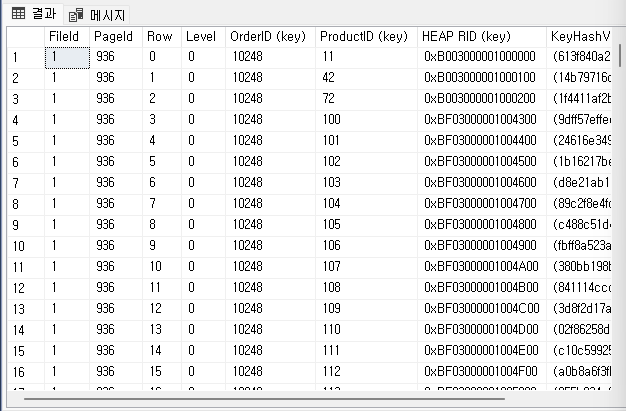
결과값을 살펴볼 경우, OrderID와 ProductID로 조회를 한다고 하더라도 OrderID의 값이 1순위로 조회되고, ProductID가 2순위로 조회되어 정렬되기 때문에 적용 테스트 4번은 적용이 되지 않는 것이다. 애시당초 OrderID로 모든 데이터 값을 정렬하기 때문이다. 따라서 ProductID를 통해 조회할 경우 데이터가 정렬이 되어있지 않기 때문에 테이블 스캔을 진행하는 것이다.
즉, Index a, b 순서로 인덱스를 만들어 줄 경우 index a는 따로 사용을 명시하지 않아도 index a의 값을 통해 정렬이 되어있기 때문에 잘 동작되어 작동한다.
인덱스는 데이터가 추가, 삭제, 갱신이 되어도 유지되어야 한다. 그렇다면 데이터를 강제로 넣게 될 경우 어떻게 처리될까? 이를 살펴보자.
-- 반복문을 통해 데이터 50개를 강제로 넣어보자.
DECLARE @i INT = 0;
WHILE @i < 50
BEGIN
INSERT INTO TestOrderDetails
VALUES (10248, 100 + @i, 10, 1, 0);
SET @i = @i +1;
END;
-- INDEX 정보 조회
DBCC IND('Northwind', 'TestOrderDetails', 2);
-- 992
-- 936 [993] 960 961 962 963 964
데이터를 넣어주고 난 이후에 Index 정보를 다시 조회할 경우, 기존에 보지 못했던 [993] 페이지가 새로 생긴 것을 알 수 있다. 이는 936에서 관리하던 데이터가 너무 많아져 이를 분리해서 관리하기 위해 페이지를 새롭게 만들어 관리하는 것을 알 수 있다. 따라서 페이지의 여유 공간이 없을 경우 페이지 분할, 스플릿(SPLIT)이 발생하는 것이다.
마지막으로 가공 테스트를 확인하고 마무리하자. 가공 테스트를 하기 위한 테이블을 또 만들어주고 인덱스를 추가해보자.
-- 가공 테스트를 위한 테이블 생성
SELECT LastName
INTO TestEmployees
FROM Employees;
-- 조회
SELECT * FROM TestEmployees;
-- LastName에 인덱스 추가
CREATE INDEX Index_TestEmployees
ON TestEmployees(LastName);
이 때, 경우에 따라 이름이 'bu'로 시작하는 애들만 모아서 찾고 싶다고 가정할 경우 Substring을 통해 이름을 자르고 검색할 경우 실행 계획은 어떻게 뜰까?
SELECT *
FROM TestEmployees
WHERE SUBSTRING(LastName, 1, 2) = 'Bu';
-- 결과 : INDEX SCAN > BAD
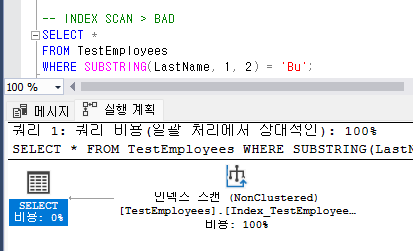
놀랍게도 LastName을 인덱스로 활용했음에도 불구하고 인덱스 스캔이 뜨는 것을 볼 수 있다. 왜 그럴까? 답은 Substring 함수 때문이다. Substring 함수에서 LastName을 어떤 방식으로 어떻게 변경할 지 모르기 때문에 SQL에서 예측을 할 수 없는 것이다.
즉, 인덱스를 걸고 이를 사용한다고 하더라도 100% 확률로 무조건 Index Seek가 뜨는 것이 아니다. 따라서 인덱스 키를 통해 조회 및 가공할 경우 굉장히 조심해야 한다. 따라서 Index Seek의 실행 계획을 갖기 위해서는 다음과 같이 변경해야 한다.
-- INDEX SEEK를 하려면?
SELECT *
FROM TestEmployees
WHERE LastName LIKE 'Bu%';
'공부 > 인프런 - Rookiss' 카테고리의 다른 글
| Part 5-3-4. SQL 튜닝 : Index Scan vs Index Seek (1) | 2024.07.10 |
|---|---|
| Part 5-3-3. SQL 튜닝 : Clustered vs NonClustered (1) | 2024.06.15 |
| Part 5-3-1. SQL 튜닝 : 인덱스 분석, RID (0) | 2024.06.02 |
| Part 5-2-19. SQL 입문 : 윈도우 함수, OVER/ROW_NUMBER/RANK/DENSE_RANK (0) | 2024.06.01 |
| Part 5-2-18. SQL 입문 : 변수와 흐름 제어, 배치/테이블 변수 (0) | 2024.05.30 |