🌞 SQL 튜닝
지난 시간에는 윈도우 함수를 통해 순위를 매기는 방법, 첫 값과 마지막 값, 이전 값과 다음 값등 다양한 윈도우 함수에 대해서 알아보았다. 이번 시간에는 인덱스 분석을 통해 인덱스를 생성하고 생성한 인덱스의 값에 대해서 알아보는 시간을 가져보도록 하자. 🧐
🍄 Northwind Database
이번 시간부터는 기존부터 사용하던 BaseballData 데이터베이스를 사용하는 것이 아닌, Northwind 데이터베이스를 사용할 것이다. 해당 데이터베이스는 설정과 관련된 정보는 아래 링크를 참조한다.
https://github.com/Microsoft/sql-server-samples/tree/master/samples/databases/northwind-pubs
sql-server-samples/samples/databases/northwind-pubs at master · microsoft/sql-server-samples
Azure Data SQL Samples - Official Microsoft GitHub Repository containing code samples for SQL Server, Azure SQL, Azure Synapse, and Azure SQL Edge - microsoft/sql-server-samples
github.com
그럼 먼저 DB 정보를 살펴보도록 하자.
-- DB 정보 살펴보기
EXEC sp_helpdb 'Northwind';

데이터베이스의 사이즈는 얼마인지, 누가 소유하고 있는지 등의 관한 정보가 나타난다.
🍄 인덱스(Index)
이제부터 정말로 인덱스를 확인하기 위해 임시 테이블을 다음과 같이 만들고 Employees 테이블을 활용하여 데이터를 넣어주자.
-- 임시 테이블 만들기 (인덱스 테스트용)
CREATE TABLE Test
(
EmployeeID INT NOT NULL,
LastName NVARCHAR(20) NULL,
FirstName NVARCHAR(20) NULL,
HireDate DATETIME NULL
);
GO
-- INSERT INTO를 통한 데이터를 Test 테이블에 넣어주자.
INSERT INTO Test
SELECT EmployeeID, LastName, FirstName, HireDate
FROM Employees;
-- 테이블에 데이터가 정상적으로 잘 들어갔는지 확인
SELECT *
FROM Test;

이제 테이블까지 만들어서 데이터를 넣었으니 실질적으로 인덱스를 생성해보도록 하자.
-- CREATE INDEX
-- FILLFACTOR (리프 페이지 공간 중 1%만 사용)
-- PAD_INDEX (FILLFACTOR 중간 페이지 적용)
CREATE INDEX Test_Index ON Test(LastName)
WITH (FILLFACTOR = 1, PAD_INDEX = ON)
GO
-- FILLFACTOR와 PAD_INDEX는 실질적으로 활용할 일이 전혀 없지만,
-- 현재는 테스트를 위해 사용하는 것으로만 알고 있자.
-- FILLFACTOR는 우리가 사용할 수 있는 전체 데이터 공간에서 단 1%만 사용한다는 뜻이다.
위와 같이 쿼리를 작성하고 실행시켜 줄 경우, 인덱스가 생성된다. 우리가 생성한 인덱스를 조회하기 위해서 다음과 같이 쿼리를 작성하고 실행하자.
-- 인덱스 번호 찾기
SELECT index_id, name
FROM sys.indexes
WHERE object_id = object_id('Test');
이 때 sys.indexes를 사용하여 인덱스를 조회한다. sys.indexes는 index에 대한 정보를 가지고 있는 아이라고 생각하면 된다.

이제 우리가 생성한 인덱스가 몇 번이지 알았으니 DBCC 키워드를 이용하여 "Northwind라는 데이터베이스에 테스트라는 2번 인덱스의 대한 정보를 보고싶다."라는 쿼리문을 작성하도록 하자.
-- 2번 인덱스에 대한 정보 살펴보기
DBCC IND('Northwind', 'Test', 2);

이 때, 알아야 할 것이 바로 인덱스 레벨이다. 인덱스 레벨은 트리 구조와 같이 생성되는데, 0이 가장 낮으며 1이 중간, 2가 제일 높다. 즉 ROOT가 레벨 2이며, Branch가 1, Leaf가 0이 된다. NextPagePID, PrevPagePID를 통해 노드에서도 순서가 있는 것을 알 수 있다. 즉 내가 만든 인덱스의 트리구조는 다음과 같다.
-- 969
-- 992 968
-- 952 960 961
그렇지만 각 페이지(PagePID)별로 무슨 정보가 있는지 추가적으로 궁금할 수 있다. 마찬가지로 DBCC 키워드와 이번에는 PAGE를 통해 해당 정보를 확인할 수 있다.
-- 각 페이지에는 무슨 정보가 있을까?
DBCC PAGE('Northwind', 1/* 파일 번호 */, 952/* 페이지 번호 */, 3 /*출력 옵션*/);
DBCC PAGE('Northwind', 1/* 파일 번호 */, 960/* 페이지 번호 */, 3 /*출력 옵션*/);
DBCC PAGE('Northwind', 1/* 파일 번호 */, 961/* 페이지 번호 */, 3 /*출력 옵션*/);
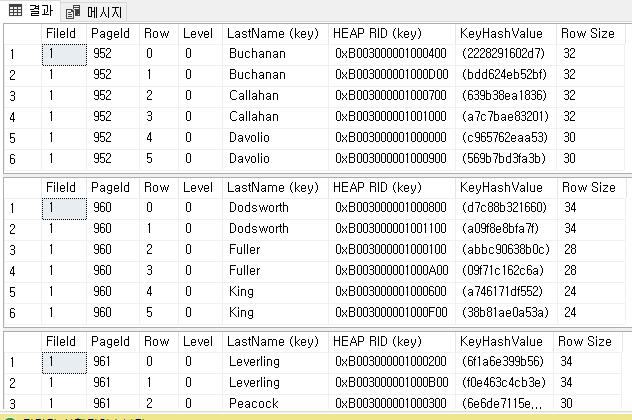
테이블 구조에서 알아야 했던 것이 인덱스 레벨이라면, 페이지에서 알아야 하는 것은 HEAP RID 줄여서 RID라고 불려지는 정보이다. RID는 [페이지 주소(4)], [파일 ID(2)], [슬롯번호(2)]로 조합한 ROW 식별자이다. 우리는 이 ROW ID를 통해 테이블에서 정보를 추출할 수 있는 것이다.
따라서 우리가 만든 인덱스의 구조는 실질적으로 테이블이라는 공간에 있는 것이며, 테이블은 일련의 페이지로 다음과 같이 나타낸다. → Table [ {Page}, {Page}, {Page}, {Page} ] 즉. RID를 통해 어떤 페이지에 어떤 정보가 있는지 찾아서 추출할 수 있는 것이며 RID는 실제 정보가 있는 위치를 뜻한다.
'공부 > 인프런 - Rookiss' 카테고리의 다른 글
| Part 5-3-3. SQL 튜닝 : Clustered vs NonClustered (1) | 2024.06.15 |
|---|---|
| Part 5-3-2. SQL 튜닝 : 복합 인덱스, 조회/SPLIT/가공 테스트 (1) | 2024.06.05 |
| Part 5-2-19. SQL 입문 : 윈도우 함수, OVER/ROW_NUMBER/RANK/DENSE_RANK (0) | 2024.06.01 |
| Part 5-2-18. SQL 입문 : 변수와 흐름 제어, 배치/테이블 변수 (0) | 2024.05.30 |
| Part 5-2-17. SQL 입문 : TRANSACTION, COMMIT/ROLLBACK (0) | 2024.05.13 |