🌞 SQL 튜닝
지난 시간에는 복합 인덱스를 통해 여러 칼럼을 동시에 인덱스를 걸어서 조회하고, 또 동시에 인덱스를 건 상태에서 특정 칼럼만 조회할 경우 어떤일이 발생하는지에 알아보았다. 이번 시간에는 인덱스의 종류인 Clustered와 Non-Clustered의 개념과 각자 동작방식은 어떻게 되는지, 마지막으로 어떤 차이점이 있는지 알아보는 시간을 가져보도록 하자. 😋
단, 이번 시간에서도 저번 시간과 마찬가지로 BaseballData 데이터베이스를 사용하는 것이 아닌, Northwind 데이터베이스를 사용할 것이다. 😎
🎞 인덱스(Index)의 종류
인덱스의 종류는 크게 2가지로 나눠 볼 수 있다. 바로 Clustered Index와 Non-Clustered Index이다.
Clustered Index의 경우 영한사전으로 이해하면 된다. 즉 모든 데이터는 키 순서로 정렬이 되는 것이다. Non-Clustered Index의 경우 색인이라고 이해하면 편하다. 즉 쪽 번호와 함께 별도로 어느 곳에 표시해놓은 상태인 것이다.
🎞 인덱스(Index)의 동작 방식
Clustered는 Leaf Page라는 잎사귀 페이지에 실질적인 모든 데이터가 들어있다. 즉 Leaf Page가 Data Page를 나타내고 이 둘이 같은 말이라고 볼 수 있다.
Non-Clustered는 Clustered Index의 유무에 따라 다르게 동작한다.
1) Non-Clustered Index 상태에서 Clustered Index가 있는 경우
- 이 경우, Heap Table이 없는 상태이므로 Clustered와 같이 Leaf Table에 실제 데이터가 존재한다. 따라서 Clustered Index가 실제 키 값을 들고 있는 상태가 된다.
2) Non-Clustered Index 상태에서 Clustered Index가 없는 경우
- 이 경우, Clustered Index라는 개념이 존재하지 않으므로, 임의의 테이블인 Heap Table에 데이터가 저장된다. 따라서 우리는 Heap RID를 통해 Heap Table에 저븐하여 데이터를 추출하고 확인한다.
이제 Clustered와 Non- Clustered의 동작방식에 대해서 알아보기 테스트 테이블을 만들어 확인해보자.
-- 임시 테스트 테이블을 만들고 데이터를 복사하자.
SELECT *
INTO TestOrderDetails
FROM [Order Details];
-- 데이터가 정상적으로 들어갔는지 확인하기 위해 조회하자.
SELECT *
FROM TestOrderDetails;
먼저, 이전 시간과 동일하게 테이블을 만들고 데이터를 복사 한 뒤에, 확인해보자. 이 후 Non-Clustered Index를 먼저 추가해 확인해보자.
-- Non-Clustered 인덱스 추가
CREATE INDEX Index_OrderDetails
ON TestOrderDetails(OrderID, ProductID);
-- 인덱스 정보 확인
EXEC sp_helpindex 'TestOrderDetails';
-- 인덱스 번호 찾기
SELECT index_id, name
FROM sys.indexes
WHERE OBJECT_ID = object_id('TestOrderDetails');
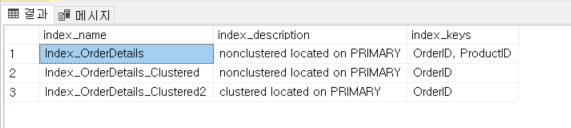
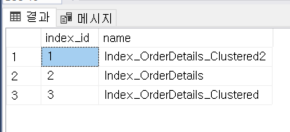
이제 인덱스 번호를 알았으니 DBCC IND 명령어를 이용해서 테이블을 조회해보자.

일전에 본 것과 같이 IndexLevel에 따라 Root - Tree - Leaf 형태로 페이지가 구성되어 있는 것을 알 수 있다. 이 때 PageType의 값이 Clustered와 Non- Clustered에 따라 달라진다. PageType 1 → Data Page, 즉 Clustered Index를 의미하며, PageType 2 → Index Page, 즉 Non- Clustered Index를 의미한다.
이 중에서도 특정 페이지를 조회해보자.
-- 페이지 조회
DBCC PAGE('Northwind', 1, 1040, 3);

이제 Non-Clustered Index를 확인했으니, Clustered Index 또한 추가하여 확인해보자.
-- Clustered Index 추가
CREATE CLUSTERED INDEX Index_OrderDetails_Clustered2
ON TestOrderDetails(OrderID);
위와 같이 쿼리를 질의하여 Clustered Index를 생성해주고, Non-Clustered를 확인할 때와 같이 인덱스 조회 및 페이지 조회를 통해 결과값을 살펴보도록 하자.
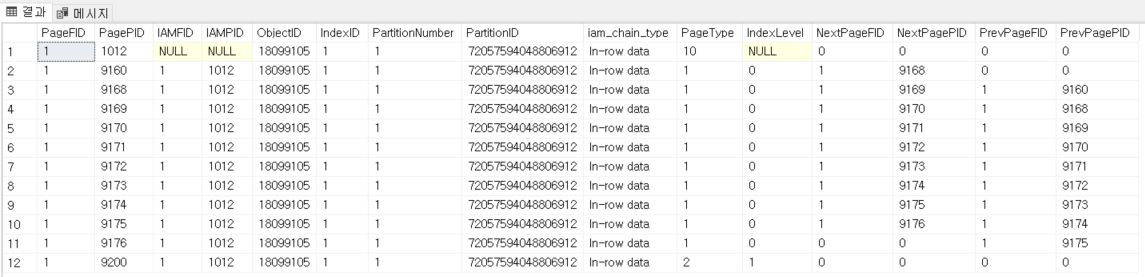
즉. Non-Clustered와 달리 Clustered 데이터는 Heap Table에 저장되는 것이 아니라, Leaf Page에 저장된다.
'공부 > 인프런 - Rookiss' 카테고리의 다른 글
| Part 5-3-5. SQL 튜닝 : 북마크 룩업 (0) | 2024.07.11 |
|---|---|
| Part 5-3-4. SQL 튜닝 : Index Scan vs Index Seek (1) | 2024.07.10 |
| Part 5-3-2. SQL 튜닝 : 복합 인덱스, 조회/SPLIT/가공 테스트 (1) | 2024.06.05 |
| Part 5-3-1. SQL 튜닝 : 인덱스 분석, RID (0) | 2024.06.02 |
| Part 5-2-19. SQL 입문 : 윈도우 함수, OVER/ROW_NUMBER/RANK/DENSE_RANK (0) | 2024.06.01 |