🌞 SQL 튜닝
지난 시간에는 인덱스의 두 가지 종류인 클러스터드 인덱스와 논클러스터드 인덱스의 개념과 동작 방식, 그리고 어떤 차이점이 있는지 알아보았다. 이번 시간에는 Index Scan과 Index Seek의 개념과 동작 방식은 어떻게 되는지, 마지막으로 어떤 방식이 더 좋은 방식인지에 대해 알아보는 시간을 가져보도록 하자. 😎
마찬가지로 이번 시간에서도 저번 시간과 마찬가지로 BaseballData 데이터베이스를 사용하는 것이 아닌, Northwind 데이터베이스를 사용할 것이다.
👜 인덱스 접근 방식
이전 시간에 간략하게 인덱스 접근 방식, 소위 엑세스를 어떻게 하는가?를 언급한 바 있다. 인덱스 접근 방식은 소위 말하는 Index Scan과 Index Seek 두 가지로 나뉘어져 있다. 오늘은 이에 대해서 좀 더 깊게 알아볼 것이다. 사실 이전 시간에 Index Scan은 무조건 나쁜거야! Index Seek는 무조건 좋은거야! 라고 했지만, 뭐든 예외가 있는법. 오늘은 예제를 통해 이를 확인하는 시간을 가져본다.
먼저 늘 그렇듯 테이블 생성 먼저 진행하도록 하자.
USE Northwind;
-- 인덱스 접근 방식 (Access)
-- Index Scan vs Index Seek
-- 테이블을 생성합니다.
CREATE TABLE TestAccess
(
id INT NOT NULL,
name NCHAR(50) NOT NULL,
dummy NCHAR(1000) NULL
);
GO
-- dummy를 용량을 크게하여 분석하기 쉽게 하도록하자. 😅
이 후, 클러스터드 인덱스와 논클러스터드 인덱스를 만들어주도록 하자.
-- 클러스터드 인덱스를 생성합니다.
CREATE CLUSTERED INDEX TestAccess_CI
ON TestAccess(id);
GO
-- 논클러스트드 인덱스를 생성합니다.
CREATE NONCLUSTERED INDEX TestAccess_NCI
ON TestAccess(name);
GO
테스트 데이터를 채워넣자.
-- 테스트 데이터를 넣습니다.
DECLARE @i INT;
SET @i = 1;
WHILE (@i <= 500)
BEGIN
INSERT INTO TestAccess
VALUES (@i, 'Name' + CONVERT(VARCHAR, @i), 'Hello World' + CONVERT(VARCHAR, @i));
SET @i = @i + 1;
END
이 후, 인덱스 정보와 번호를 확인하고 이를 토대로 테이블을 조회하도록 하자.
-- 인덱스 정보 확인
EXEC sp_helpindex 'TestAccess';
-- 인덱스 번호 확인
SELECT index_id, name
FROM sys.indexes
WHERE object_id = object_id('TestAccess');
-- 테이블 조회
DBCC IND('Northwind', 'TestAccess', 1);
DBCC IND('Northwind', 'TestAccess', 2);


이 후 테이블 조회 값을 바탕으로 클러스트가 어떤 식으로 생성되었는지를 살펴보도록 하자. 나와 같은 경우는 아래와 같이 구성되어 있는 것을 알 수 있다.
-- CLUSTERED(1) : id
-- 8097
-- 944 945 946 ~ 8103 (167)
-- CLUSTERED(2) : name
-- 936
-- 937 938 ~ 939 (13)
이제 이를 바탕으로 실행 계획을 실질적으로 분석해보자!
먼저 실행했을 때 논리적 읽기*가 얼마나 나왔는지 확인하기 위해 아래와 같은 쿼리를 작성하고, 매 결과 조회시마다 아래 쿼리를 실행하여 확인하도록 하자.
*논리적 읽기 : 실제 데이터를 찾기 위해 읽어들인 페이지의 수
SET STATISTICS TIME ON;
SET STATISTICS IO ON;
먼저 첫번째다.
-- INDEX SCAN → Leaf Page를 순차적으로 검색
SELECT *
FROM TestAccess;
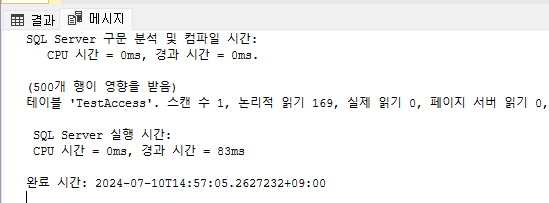
그렇다면 '169'라는 수는 어떻게 나왔을까? 먼저 Index Scan을 하고 있기 때문에 8097번 페이지부터 순차적으로 읽어들인 후, 944번 Leaf Page를 읽고 그 이후에 마지막 Leaf Page인 8103번까지 순차적으로 검색하여 읽을 것이다.
결국 Index Scan은 Leaf Page를 순차적으로 검색하는 것이기 때문에 최상위 8097번부터 8103번까지 하나씩 이동하여 스캔했기 때문에 169라는 수가 나타난다.
다음은 두번째다.
-- INDEX SEEK →
-- 논리적 읽기 횟수가 2밖에 안됌!
SELECT *
FROM TestAccess
WHERE id = 104;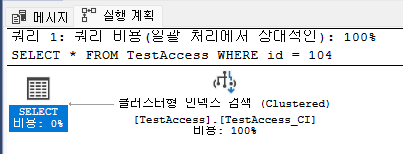

마찬가지로 Index Seek가 나왔을 경우 '2'라는 수는 어떻게 나왔을까? 이전과는 반대로 지금은 Index Seek을 하고 있지만, id는 클러스터드 인덱스로 설정해주었기 때문에 8097에게 한번 들어온 후, 104번의 키가 어디있는지 물어보고 그 다음 알맞는 페이지로 넘어가 데이터를 찾아 '2'번만에 데이터를 찾은 것을 볼 수 있다.
다음은 세번째이다.
-- 논클러스트에서 실행
-- INDEX SEEK + KEY LOOKUP
-- 논리적 읽기 횟수 4, KEY LOOKUP(?)도 생김
SELECT *
FROM TestAccess
WHERE name = 'name5';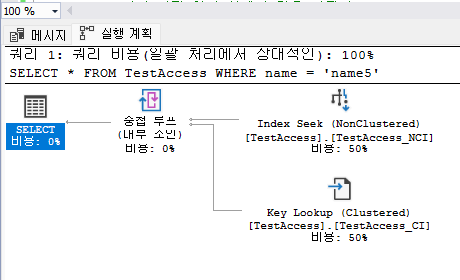
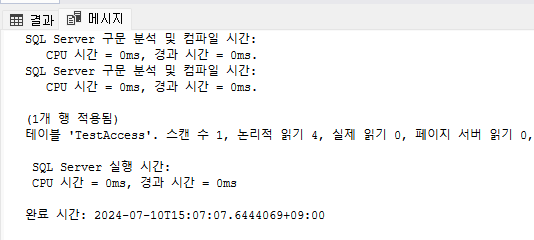
기존에 볼 수 없던 Key LookUp이라는 개념이 새롭게 나타났다. 이는 Index Seek만으로 끝낼 수 있는 것이아니라 Key LookUp이라는 개념까지 함께 사용해서 처리해야 하는 것이다. 해당 개념은 나중에 알아보도록 하자.
그렇다면 '4'라는 수는 어디서 나왔을까? 지금부터는 논클러스트를 조회하고 있기 떄문에 클러스터드 인덱스의 키값만 가지고 있는 상황이다. 따라서 Name5에 해당하는 id 값만 가지고 있다. 따라서 id값을 바탕으로 클러스트 인덱스로 접근해주야 한다. 클러스트 인덱스로 접근 한 이후에 id값을 바탕으로 다시 찾게 된다. 이러한 프로세스에 거쳐 논 클러스트에서 1, 2 스텝, 클러스트에서 3, 4의 스텝을 밟게 되어 '4'라는 값을 가지게 된다.
마지막이다.
-- INDEX SCAN + KEY LOOKUP
-- 경우에 따라 INDEX SCAN이 나쁜것은 아닌데, 이 상황이 바로 그 상황이다.
SELECT TOP 5 *
FROM TestAccess
ORDER BY name;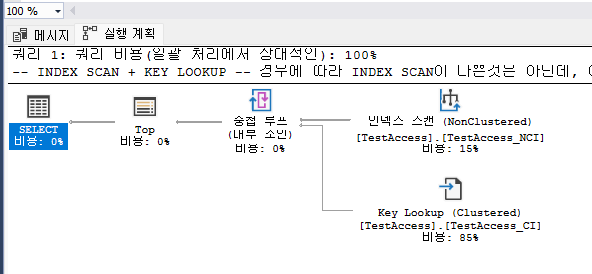

이번에는 논클러스트를 조회했음에도 불구하고 Index Scan이 나왔지만 '13'개의 페이지만 읽어들인 것을 볼 수 있다. 왜 이렇게 적은 값이 나타났을까?
해답은 바로 TOP와 ORDER BY에 있다. Name은 논클러스트 인덱스이므로 논클러스트 테이블의 Leaf Page만 순회하면 되고 애시당초 TOP5만 출력하기 때문에 오래걸리지 않는 것이다.
👜 결론
그렇다면 Index Scan이 좋을까? Index Seek가 좋을까? 라고 묻는다면 답은 케이스 바이 케이스가 된다. 위 예제를 통해 알 수 있듯이 무조건 Index Seek의 실행계획을 가진다고해서 좋은 것이 아니고, Index Scan의 실행계획을 가진다고해서 나쁜 것도 아니다. 🤣
'공부 > 인프런 - Rookiss' 카테고리의 다른 글
| Part 5-3-6. SQL 튜닝 : 인덱스 컬럼 순서 (1) | 2024.07.12 |
|---|---|
| Part 5-3-5. SQL 튜닝 : 북마크 룩업 (0) | 2024.07.11 |
| Part 5-3-3. SQL 튜닝 : Clustered vs NonClustered (1) | 2024.06.15 |
| Part 5-3-2. SQL 튜닝 : 복합 인덱스, 조회/SPLIT/가공 테스트 (1) | 2024.06.05 |
| Part 5-3-1. SQL 튜닝 : 인덱스 분석, RID (0) | 2024.06.02 |