💅 SQL 입문
지난 시간에는 변수와 흐름제어를 통해 SQL에서 변수 선언 및 배치, 흐름 제어를 하는 방법에 대해서 알아보았다. 이번 시간에서는 윈도우 함수를 통해 보다 다른 방식의 GROUPING을 이용하는 방법에 대해서 알아보는 시간을 가지자. 😊
🚲 윈도우 함수
윈도우 함수란 무엇일까? 이름이 윈도우 함수라서 윈도우 운영체제에서만 돌아간다고 착각할 수 있지만, 그런 것은 아니다. 한 줄로 요약하자면 행들의 서브 집합을 대상으로, 각 행별로 계산을 해서 스칼라(단일 고정) 값을 출력하는 함수이다. 설명이 조금 어렵지만, 느낌상 그룹핑과 유사하다는 것을 느낄 수 있다.
그룹핑은 어떤 집합은 아니지만, 여러 기준을 대상으로 데이터를 보기 좋게 확인한 다음 단일 고정값을 추출했다. SUM, COUNT, AVG를 예로 들 수 있다. 그러나 그룹핑의 단점이 있는데, 그 단점이 데이터의 일부가 그냥 소멸된다는 문제이다. 예를 들어보자.
-- 그룹핑의 예, 연봉을 높은 순서대로 확인한다.
SELECT *
FROM salaries
ORDER BY salary DESC;
-- 그러나 여기서 playerID를 확인하고 싶다고 할 경우 다음과 같이 작성할 수 있다.
SELECT playerID, MAX(salary)
FROM salaries
GROUP BY playerID
ORDER BY MAX(salary) DESC;
-- 이 경우, 데이터 소실의 문제가 발생한다.
-- playerID를 통해 정보를 확인 할 경우 yearID, salary와 같은 정보는 더이상 사용할 수 없게 되는 것이다.
따라서 위 문제를 해결하기 위해 나타난 것이 윈도우 함수이다.
🚲 ROW_NUMBER, RANK, DENSE_RANK
윈도우 함수를 사용하기 위해서는 문법적으로 OVER 키워드를 사용해야 한다. OVER는 [PARTIOTION] [ORDER BY] [ROWS] 와 같은 요소를 사용하지만 위 세 요소를 필수적으로 사용하는 것은 아니다. 이제 윈도우 함수를 통해 연봉 순서를 순위를 매겨보도록 하자. 그러나 순위를 매기는 방법에도 여러 문제가 존재한다. 공동 1위는 어떻게 처리할 것인지, 공동 1위가 있을 때 다음 순위는 2위로 할지, 3위로 할지 등 따라서 순위를 매기는 함수도 다양하게 존재한다.
-- 전체 데이터를 연봉 순서로 나열하고, 순위를 표기해보자.
SELECT *,
ROW_NUMBER() OVER (ORDER BY salary DESC), -- 행#번호
RANK() OVER (ORDER BY salary DESC), -- 랭킹
DENSE_RANK() OVER (ORDER BY salary DESC), -- 랭킹
NTILE(100) OVER (ORDER BY salary DESC) -- 백분율 (상위 몇 %)
FROM salaries;

ROW_NUMBER는 말 그대로 행 번호를 애기한다. 따라서 별다른 것은 없고 그냥 행 번호를 나타낸다. RANK는 공동 1위를 다 1등으로 표시하지만 2위는 2등이 아닌 3등으로 표시를 처리한다. DENSE_RANK와 같은경우 공동 1위를 다 1등으로 표시하지만 2위는 3등이 아닌 2등으로 표시를 처리한다. 마지막으로 백분율은 말 그대로 상위 몇 %인지를 알려준다.
그렇지만 경우에 따라서 전체 데이터 기준이 아닌 일부 데이터를 바탕으로 윈도우 함수를 사용할 경우가 생긴다. 따라서 이전처럼 연봉을 바탕으로 데이터를 전체 조회하는 것이 아닌 플레이어 아이디 별로 순위를 따로 보는 경우에 대해서 살펴보자.
-- playerID 별 순위를 따로 하고 싶다면
SELECT *,
RANK() OVER (PARTITION BY playerID ORDER BY salary DESC)
FROM salaries
ORDER BY playerID;

위 쿼리문은 자기 연도별 연봉에 따라 자기 자신만의 순위를 가지는 것을 볼 수 있다. 따라서 이 경우 Partition을 이용한 Subset을 따로 지정해 처리할 수 있다. 이러한 점을 비롯하여 GROUPBY와 비슷하지만, GROUPBY의 경우 행별로 세부 정보에 대한 데이터 조회가 불가능 하지만, 윈도우 함수는 이러한 것들이 가능 한 것을 알 수 있다.
🚲 LAG, LEAD, FIRST VALUE, LAST VALUE
이 외에도 다양한 윈도우 함수의 종류가 있다. 그렇지만 모든 것을 다 소개한다고 해서 외워지지도 않고 필요없으므로 그때 그때 필요할 때 문서를 찾아보면서 사용하도록 하자. 그 중에서도 자주 사용하는 LAG, LEAD에 대해서 알아보자. 각각의 함수는 이전 값, 다음 값을 보여준다.
-- LAG(바로 이전), LEAD(바로 다음)
SELECT *,
RANK() OVER (PARTITION BY playerID ORDER BY salary DESC),
LAG(salary) OVER (PARTITION BY playerID ORDER BY salary DESC) AS prevSalary,
LEAD(salary) OVER (PARTITION BY playerID ORDER BY salary DESC) AS prevSalary
FROM salaries
ORDER BY playerID;

그 다음으로는 FIRST VALUE, LAST VALUE에 대해서 알아보자. FIRST VALUE는 첫 값, LAST VALUE는 마지막 값을 나타낸다.
-- FIRST VALUE(첫 값), LAST VALUE(마지막 값)
-- FRAME : FIRST ~ CURRENT
SELECT *,
RANK() OVER (PARTITION BY playerID ORDER BY salary DESC),
FIRST_VALUE(salary) OVER (PARTITION BY playerID ORDER BY salary DESC) AS best,
LAST_VALUE(salary) OVER (PARTITION BY playerID ORDER BY salary DESC) AS worst
FROM salaries
ORDER BY playerID;
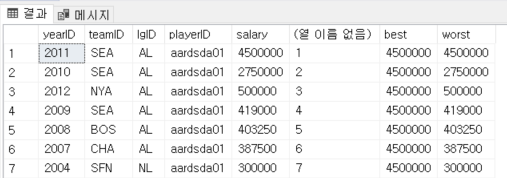
그러나 위 쿼리를 실행할 경우 worst의 값이 정상적으로 나오지 않는데 worst는 현재 행에서 가장 작은 값을 찾으므로 문제가 되는 것이다. 즉 1번 행에서는 값이 4,500,000이 되고, 2번 행에서는 2,750,000의 값이 되며 3번 행에서부터 500,000이 된 걸 볼 수 있다. 따라서 이를 해결하기 위해서는 ROW의 값을 다음과 같이 설정하여 수정해주어야 한다.
SELECT *,
RANK() OVER (PARTITION BY playerID ORDER BY salary DESC),
FIRST_VALUE(salary) OVER (PARTITION BY playerID
ORDER BY salary DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS best,
LAST_VALUE(salary) OVER (PARTITION BY playerID
ORDER BY salary DESC
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
) AS worst
FROM salaries
ORDER BY playerID;
-- UNBOUNDED PRECEDING는 무한으로 앞으로 가도 된다. 뜻
-- UNBOUNDED FOLLOWING는 앞으로 가다. 뜻 즉 처음부터 나까지. 나부터 마지막까지의 의미가 된다.
위와 같이 질의를 수정해준다면 우리가 생각했던 것과 같이 값이 나오는 것을 볼 수 있다.
'공부 > 인프런 - Rookiss' 카테고리의 다른 글
| Part 5-3-2. SQL 튜닝 : 복합 인덱스, 조회/SPLIT/가공 테스트 (1) | 2024.06.05 |
|---|---|
| Part 5-3-1. SQL 튜닝 : 인덱스 분석, RID (0) | 2024.06.02 |
| Part 5-2-18. SQL 입문 : 변수와 흐름 제어, 배치/테이블 변수 (0) | 2024.05.30 |
| Part 5-2-17. SQL 입문 : TRANSACTION, COMMIT/ROLLBACK (0) | 2024.05.13 |
| Part 5-2-16. SQL 입문 : JOIN, CROSS/INNER/LEFT/RIGHT JOIN (0) | 2024.05.09 |