
본 포스팅은 '밑바닥부터 시작하는 딥러닝2'를 읽고 공부 및 학습 내용을 정리한 글입니다. 언제든지 다시 참고할 수 있도록, 지식 공유보단 개인적인 복습을 목적으로 포스팅하였습니다.
4.1 word2vec 개선 ①
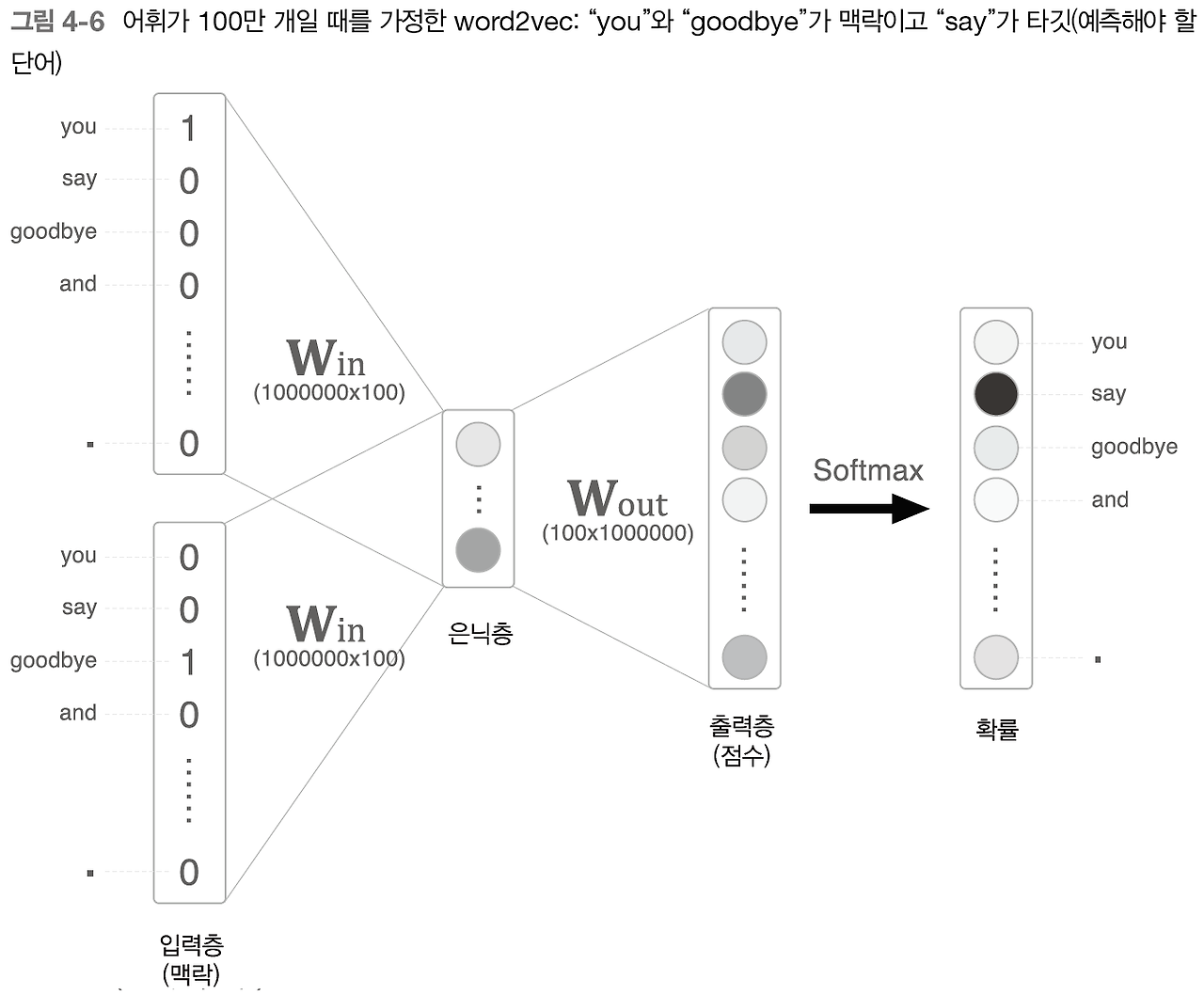
3장에서 구현한 CBOW모델은 단어 2개를 맥락으로 이용해 하나의 단어(target)을 추측했다. 그러나 이 때에는 말뭉치를 7개만 사용했는데 실제로는 더 거대한 말뭉치를 사용하게 되는데 이 때 문제가 발생한다.
만약 100만개의 말뭉치 데이터를 사용한다고 하면 많은 뉴련으로 인해 두 계산의 병목 현상이 생긴다.
1. 입력층의 원핫 표현과 가중치 행렬 Win의 곱 계산
2. 은닉층과 가중치 행렬 Wout의 곱 및 Softmax 계층의 계산
1번은 입력층의 원핫 표현과 관련된 문제이며, 100만개를 원핫 벡터로 표현한다고 할 경우 100만개의 원핫 벡터가 생기기 때문에 메모리를 많이 차지하게 된다. 따라서 이는 4.1절에서 해결할 것이다.
2번은 은닉층 이 후의 계산이다. 어휘가 증가함에따라 마찬가지로 계산량도 증가하게 되는데 이 문제는 4.2절에서 해결 할 것이다.
4.1.1 Embedding 계층
그림 4-3은 기존 CBOW 모델에서 원핫 표현과 Matmul을 통해 데이터를 구하는 것을 행렬의 특정 행을 추출하는 것으로 대신한다. 따라서 불필요한 계산을 하지 않는 것이다. 이 때 가중치 매개변수로 부터 단어 id에 해당하는 행을 추출하고 이를 계층으로 만드는 것을 embedding 계층이라 한다.
4.1.2 Embedding 계층 구현
4.2 word2vec 개선 ②
남은 병목 현상인 은닉층 이후의 처리를 해결한다.
4.2.1 은닉층 이후 계산의 문제점
마찬가지로 거대한 말뭉치로 인한 계산의 부하가 걸리는 곳은 1. 은닉층의 뉴런과 가중치를 곱하는 부분과 2. SoftMax 를 통해 계산하는 부분이다. 마찬가지로 1번 또한 거대한 행렬을 곱하는 문제이기 때문에 이 행렬을 최대한 가볍게 만들어야 한다.
4.2.2 다중 분류에서 이진 분류로
다중 분류와 이진 분류 챕터에서 갑자기 네거티브 샘플링의 얘기가 나오지만, 네거티브 샘플링의 핵심 아이디어는 이진 분류에 있다. 보다 정확하게 말하자면 '다중 분류'이다. 지금까지 학습해 온 내용으로는 우리는 문제를 다중 분류로만 다루고 풀었다. 하지만 이진 분류로 문제를 다룰수는 없을까? 이 부분도 보다 정확하게 말하자면 다중 분류 문제를 이진 분류로 근사할수는 없을까?가 된다.
이진 분류로 문제를 해결 할 경우 출력층에는 뉴런을 하나만 준비하면 된다.
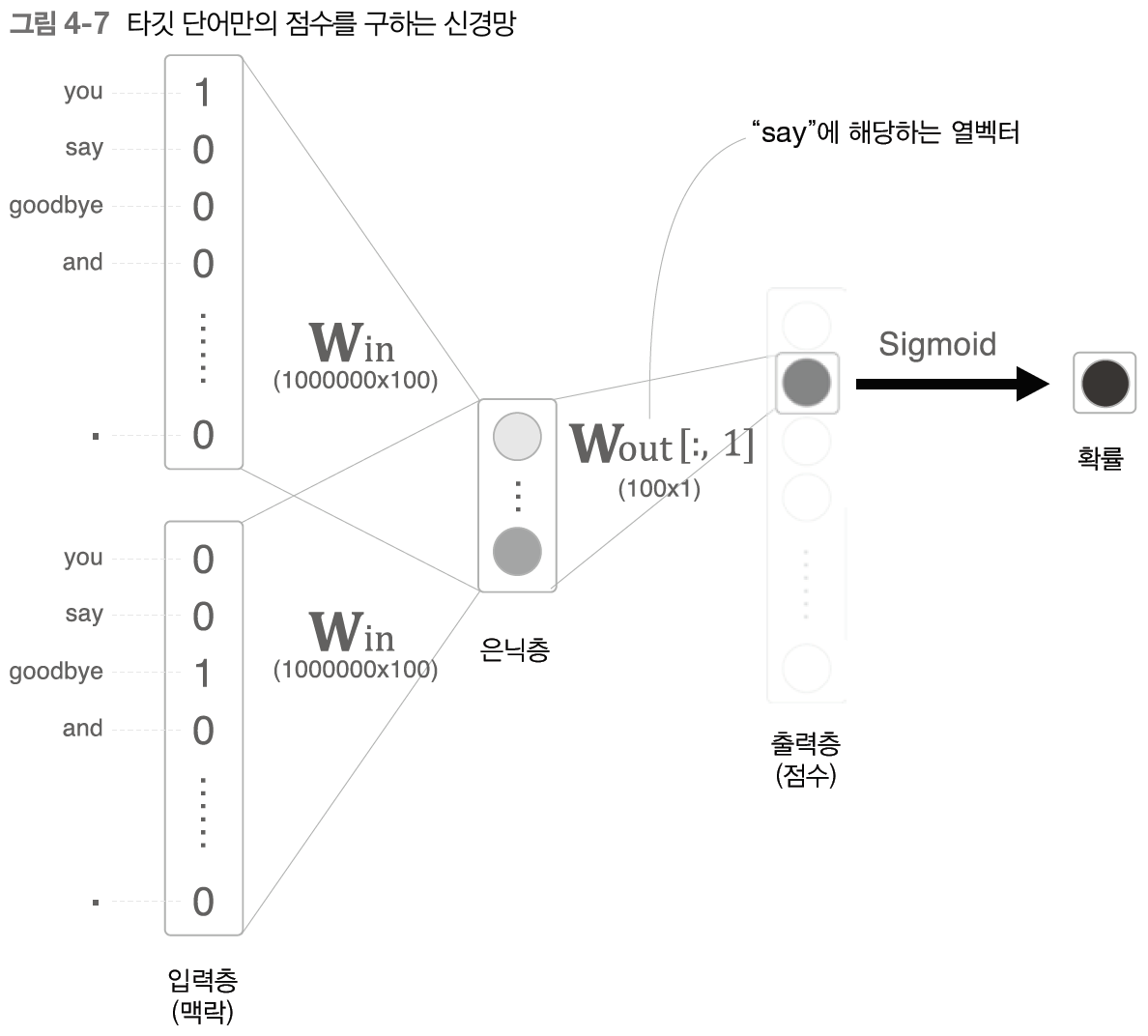
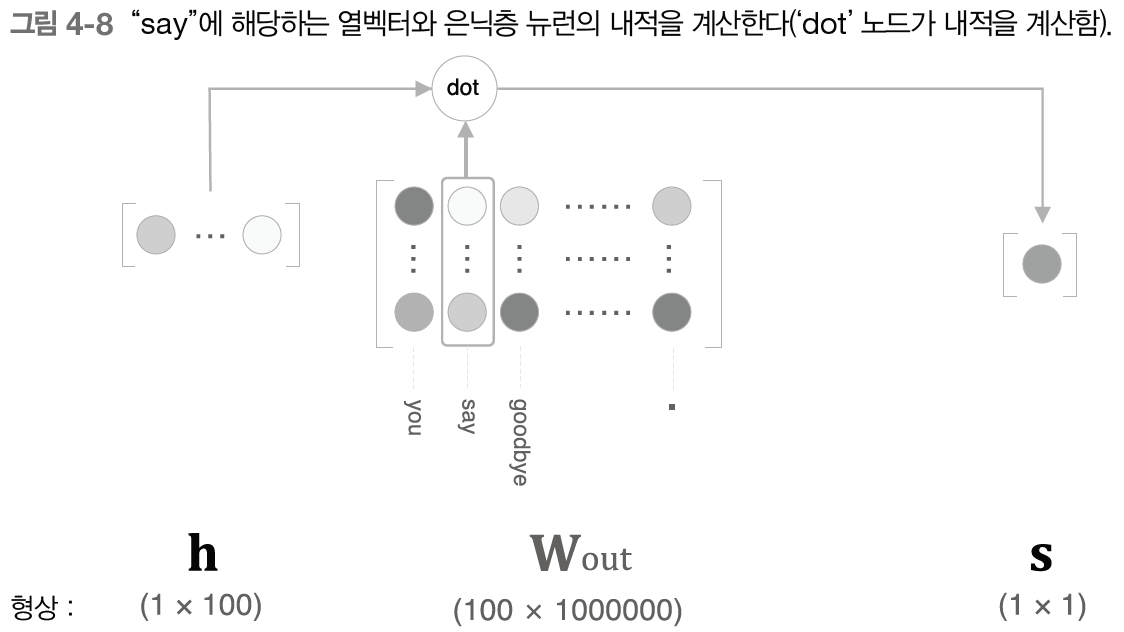
4.2.3 시그모이드 함수와 교차 엔트로피 오차
이진 분류 문제를 신경망으로 풀기 위해서는 점수에 시그모이드 함수를 적용해 확률로 변환하고 손실을 구할 때는 손실 함수로 교차 엔트로피 오차를 사용한다. 시그모이드는 이전에 한번 학습했다. 33p를 참고한다.
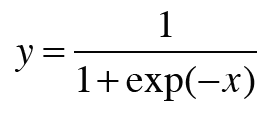
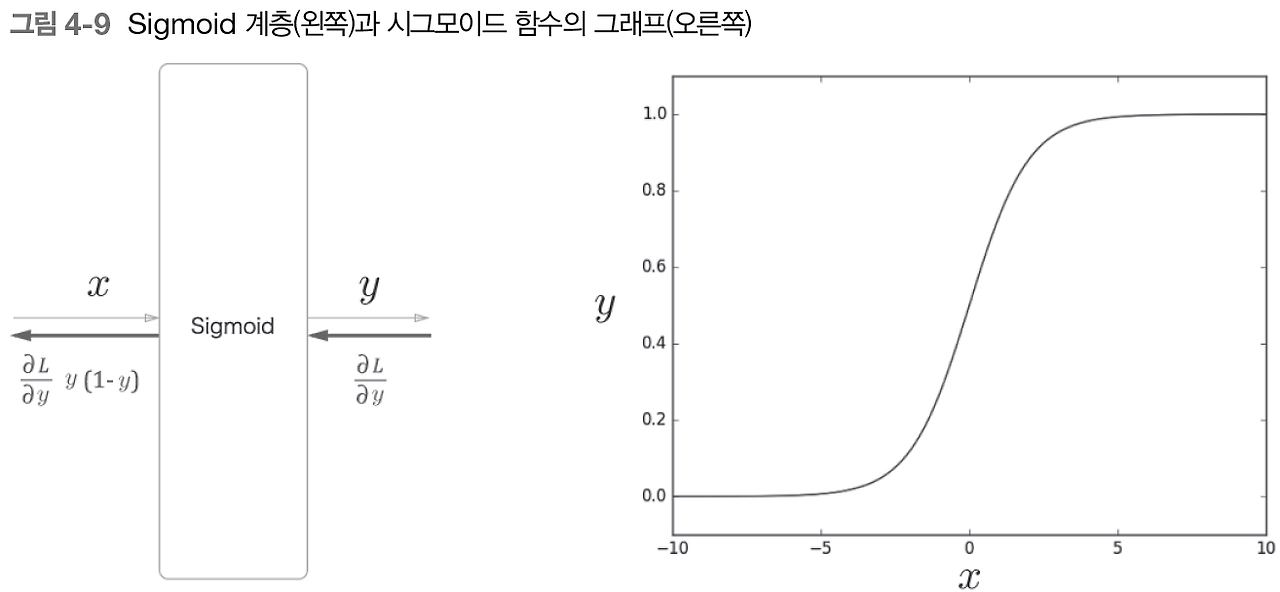
위와 같이 시그모이드 함수를 적용해 확률 y를 얻으면 이 확률 y로 부터 손실을 구한다.
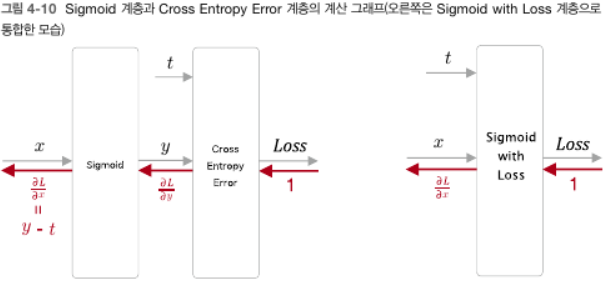
이 후 역전파의 y−t 값은 곧 신경망이 출력한 확률과 정답 레이블의 차이가 된기 때문에 오차가 앞 계층으로 흘러가므로 오차가 크면 '크게', 오차가 작으면 '작게' 학습하게 된다.
4.2.4 다중 분류에서 이진 분류로 (구현)
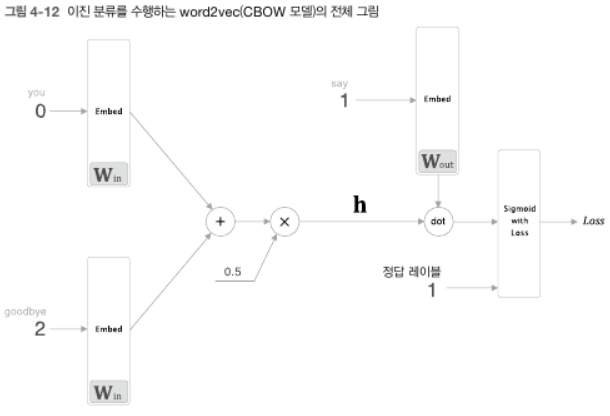
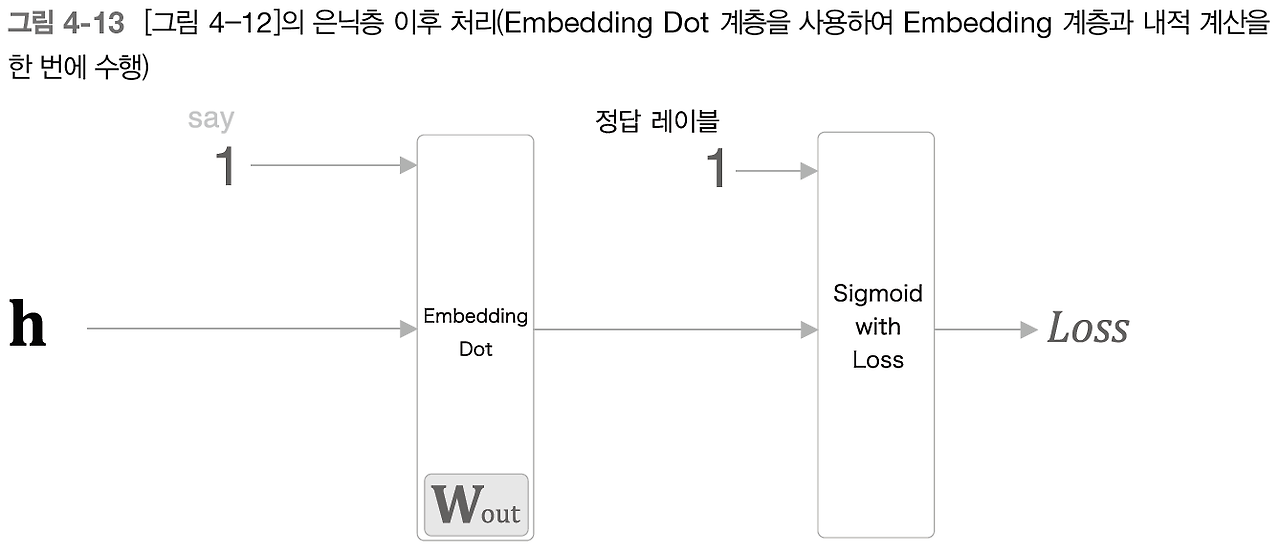
dot 부분을 보다 간단하게 계산하여 sigmoid with Loss 계층으로 이를 한번에 수행하도록 한다.
4.2.5 네거티브 샘플링
다중 분류를 이중 분류로 바꾸는 방법을 통해 우리는 현재 '정답'에 대해서만 학습했다. 다시말해 현재 상태에서 오답을 입력 할 경우 어떤 결과가 나올지 확실하지 않다. 따라서 우리가 원하는 것은 “say”가 나올 확률은 1에 가깝도록, 그 외 나머지 단어들이 나올 확률은 0에 가깝도록 학습시켜야한다.
이를 위해서 적절한 수의 부정적 예시에 대해서도 학습을 진행한다. 이를 네거티브 샘플링이라고 한다. 보다 정확히는 정답 샘플에서의 손실과 오답 샘플에서의 손실을 더한 값을 최종 손실로 하여 학습한다. 라고 볼 수 있다.
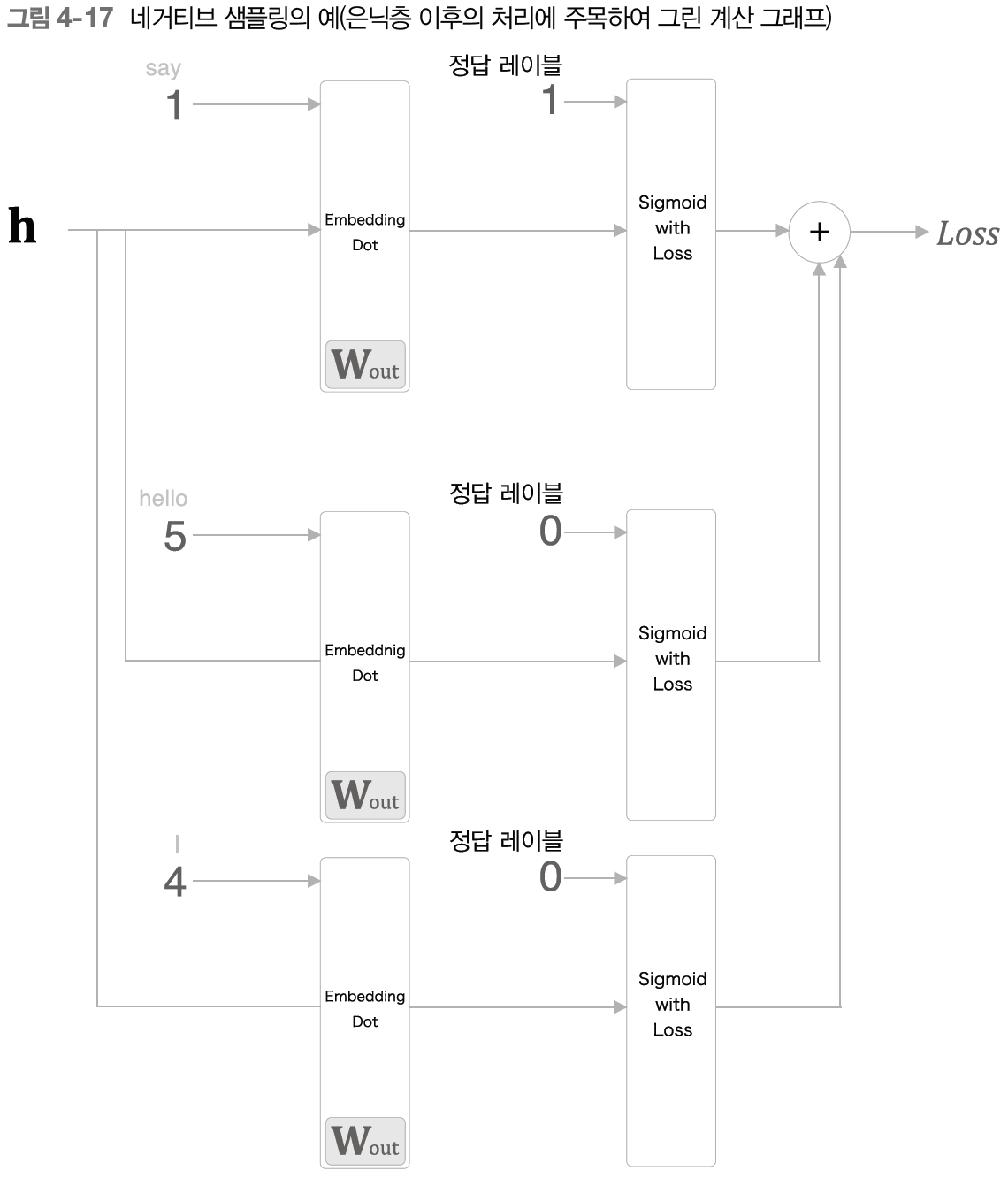
4.2.6 네거티브 샘플링의 샘플링 기법
그렇다면 오답은 어떻게 샘플링해야 할까? 무식하게 무작위로 샘플링하는 것보다 말뭉치의 통계 데이터를 통해 샘플링하는 것이 가장 좋다. 이렇게 될 경우 자주 등장하는 단어는 많이 추출하고, 드물게 등장하는 단어는 적게 추출하는 것이다. 넘파이의 random.choice() 함수를 이용하면 확률 분포에 따른 샘플링 처리를 할 수 있다.
여기서 추가적으로 확률분포를 수정해줘야 한다. 아래 이미지와 같은 새로운 확률분포를 사용하는 것이다. 이렇게 변경하는 이유는 출현 확률이 낮은 단어를 버리지 않기 위해서이다. 0.75 제곱을 함으로서 원래 확률이 낮은 단어의 확률을 살짝 높일 수 있다.
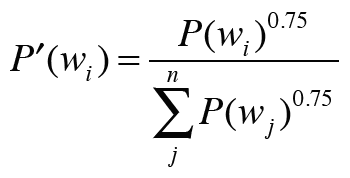
이는 실제 현업에서도 사용된다. 단순히 네거티브 샘플링 기법 중 내용의 일부는 아니며 ChatGPT에서도 정치적이나 폭력적인 내용으로 검색할 때 이를 회피하기 위해 네이티브 샘플링을 통해 처리한다.
결론적으로 네거티브 샘플링은 말뭉치에서 단어의 확률분포를 만들고, 이를 0.75를 제곱한 다음 부정적 예를 샘플링한다.
4.2.7 네거티브 샘플링 구현
from common.layers import SigmoidWithLoss
class NegativeSamplingLoss:
def __init__(self, W, corpus, power=0.75, sample_size=5):
self.sample_size = sample_size
self.sampler = UnigramSampler(corpus, power, sample_size)
self.loss_layers = [SigmoidWithLoss() for _ in range(sample_size + 1)]
self.embed_dot_layers = [EmbeddingDot(W) for _ in range(sample_size + 1)]
self.params, self.grads = [], []
for layer in self.embed_dot_layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, h, target):
batch_size = target.shape[0]
negative_sample = self.sampler.get_negative_sample(target)
# 긍정적 예 순전파
score = self.embed_dot_layers[0].forward(h, target)
correct_label = np.ones(batch_size, dtype=np.int32)
loss = self.loss_layers[0].forward(score, correct_label)
# 부정적 예 순전파
negative_label = np.zeros(batch_size, dtype=np.int32)
for i in range(self.sample_size):
negative_target = negative_sample[:, i]
score = self.embed_dot_layers[1 + i].forward(h, negative_target)
loss += self.loss_layers[1 + i].forward(score, negative_label)
return loss
def backward(self, dout=1):
dh = 0
for l0, l1 in zip(self.loss_layers, self.embed_dot_layers):
dscore = l0.backward(dout)
dh += l1.backward(dscore)
return dh
4.3 개선된 word2vec 학습
4.3.1 CBOW 모델 구현
앞에서 배운 Embedding 계층과 NegativeSamplingLoss 계층을 통해 CBOW 모델 구현을 새롭게 구현 해보자.

4.3.2 CBOW 모델 학습 코드
import numpy as np
import pickle
from common.trainer import Trainer
from common.optimizer import Adam
from dataset import ptb
from common.util import create_contexts_target
# 하이퍼파라미터 설정
window_size = 5
hidden_size = 100
batch_size = 100
max_epoch = 10
# 데이터 읽기
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size)
# 모델 등 생성
model = CBOW(vocab_size, hidden_size, window_size, corpus)
optimizer = Adam()
trainer = Trainer(model, optimizer)
# 학습 시작
trainer.fit(contexts, target, max_epoch, batch_size)
# trainer.plot()
# 나중에 사용할 수 있도록 필요한 데이터 저장
word_vecs = model.word_vecs
params = {}
params['word_vecs'] = word_vecs.astype(np.float16)
params['word_to_id'] = word_to_id
params['id_to_word'] = id_to_word
pkl_file = 'cbow_params.pkl'
with open(pkl_file, 'wb') as f:
pickle.dump(params, f, -1)
실제로 돌리면 매우 느리기 때문에 책에서 제공하는 학습이 완료된 매개변수를 이용하도록 하자.
4.3.3 CBOW 모델 평가
앞에서 학습한 단어의 분산 표현을 평가해보자. most_similar() 메서드를 통해, 특정 단어에 대해 거리가 가장 가까운 단어들을 뽑아보자.
from common.util import most_similar
pkl_file = 'cbow_params.pkl'
with open(pkl_file, 'rb') as f:
params = pickle.load(f)
word_vecs = params['word_vecs']
word_to_id = params['word_to_id']
id_to_word = params['id_to_word']
querys = ['you', 'year', 'car', 'toyota']
for query in querys:
most_similar(query, word_to_id, id_to_word, word_vecs, top=5)
#---------------------출력---------------------#
# [query] you
# we: 0.6103515625
# someone: 0.59130859375
# i: 0.55419921875
# something: 0.48974609375
# anyone: 0.47314453125
# [query] year
# month: 0.71875
# week: 0.65234375
# spring: 0.62744140625
# summer: 0.6259765625
# decade: 0.603515625
# [query] car
# luxury: 0.497314453125
# arabia: 0.47802734375
# auto: 0.47119140625
# disk-drive: 0.450927734375
# travel: 0.4091796875
# [query] toyota
# ford: 0.55078125
# instrumentation: 0.509765625
# mazda: 0.49365234375
# bethlehem: 0.47509765625
# nissan: 0.474853515625
실행의 결과로는 'you’에 대해서는 비슷한 단어로 인칭대명사 ‘I’와 ‘we’ 등이 나온 걸 볼 수 있다. ‘year’에 대해서는 ‘month’와 ‘week’ 같은 기간을 뜻하는 단어들이 나왔으며, ‘toyota’에 대해서는 ‘ford’, ‘nissan’같은 자동차 메이커가 나왔다. 이 결과를 보면 CBOW 모델로 획득한 단어의 분산 표현은 제법 괜찮은 특성을 지닌다고 볼 수 있다.
또한 word2vec으로 얻은 단어의 분산 표현은 비슷한 단어를 가까이 모을 뿐 아니라, 더 복잡한 패턴 까지 파악하는 것으로 알려져 있다. 대표적인 예가 “king - man + woman = queen”이다. 더 정확히 말하면 word2vec의 단어의 분산 표현을 사용하면 유추 문제를 벡터의 덧셈과 뺄셈으로 풀 수 있다는 뜻이다.
4.4 word2vec 남은 주제
4.4.1 word2vec을 사용한 애플리케이션의 예
단어의 분산표현이 중요한 이유는 바로 '전이 학습'에 있다. 전이 학습은 한 분야에서 배운 지식을 다른 분야에도 적용하는 뜻이다. 자연어 문제를 풀 때 word2vec의 단어 분산 표현을 처음부터 학습하는 일은 거의 없다. 그 대신 먼저 큰 말뭉치로 학습을 끝난 후, 그 분산 표현을 각자의 작업에 이용하게 된다. 예를 들어 텍스트 분류, 문서 클러스터링, 품사 태그 갈기, 감정 분석 등 자연어 처리 작업이라면 가장 먼저 단어를 벡터로 변환하는 작업을 해야하는데, 이때 학습을 미리 끝낸 단어의 분산 표현을 이용할 수 있다.
단어의 분산 표현은 단어를 고정 길이 벡터로 변환해준다는 장점도 있다. 게다가 문장도 단어의 분산 표현을 사용하여 고정 길이 벡터로 변환할 수 있다. 문장을 고정 길이 벡터로 변환하는 방법은 활발하게 연구되고 있는데, 가장 간단한 방법은 문장의 각 단어를 분산 표현으로 변환하고 그 합을 구하는 것이다.
4.4.2 단어 벡터 평가 방법
word2vec을 통해 얻은 단어의 분산 표현이 좋은지는 어떻게 평가할까? 자주 사용되는 평가 척도로는 단어의 ‘유사성’이나 ‘유추 문제’를 활용한 평가이다.
단어의 유사성 평가에서는 사람이 작성한 단어 유사도를 검증 세트를 사용해 평가하는 것이 일반적이다. 예를 들어 유사도를 0에서 10사이로 점수화한다면, “cat”과 “animal”의 유사도는 8점, “cat”과 “car”의 유사도는 2점과 같이, 사람이 단어 사이의 유사한 정도를 규정한다. 그리고 사람이 부여한 점수와 word2vec에 의한 코사인 유사도 점수를 비교해 그 상관성을 보는 것이다.
유추 문제를 활용한 평가는 “king : queen = man : ?”와 같은 유추 문제를 출제하고, 그 정답률로 단어의 분산 표현의 우수성을 측정한다. 유추 문제를 이용하면 ‘단어의 의미나 문법적인 문제를 제대로 이해하고 있는지’를 측정할 수 있다.
4.5 정리
1. Embedding 계층은 단어의 분산 표현을 담고 있으며, 순전파 시 지정한 단어 ID의 벡터를 추출한다.
2. word2vec은 어휘 수의 증가에 비례하여 계산량도 증가하므로, 근사치로 계산하는 빠른 기법을 사용하면 좋다.
3. 네거티브 샘플링은 부정적 예를 몇 개 샘플링하는 기법으로, 이를 이용하면 다중 분류를 이진분류처럼 취급할 수 있다.
4. word2vec으로 얻은 단어의 분산 표현에는 단어의 의미가 녹아들어 있으며, 비슷한 맥락에서 사용되는 단어는 단어 벡터 공간에서 가까이 위치한다.
5. word2vec의 단어의 분산 표현을 이용하면 유추 문제를 벡터의 덧셈과 뺄셈으로 풀 수 있게 된다.
6. word2vec은 전이학습 측면에서 특히 중요하며, 그 단어의 분산 표현은 다양한 자연어 처리 작업에 이용할 수 있다.
4.6 소감
곰곰히 생각해보니 단순히 'word2vec'는 문제를 해결할 수 없다는 걸 나중에 깨달았다. 따라서 전이학습 장에서도 얘기했듯이 이 'word2vec'에서 나온 결과물을 가지고 어떻게 설정해주고, 요리하냐에 따라 사용할 곳이 정말 무궁무진하게 많겠구나. 생각했다.
또한 강의에서 들었던 얘기로는 데이터는 다다익선이 좋다고 했는데, 데이터가 늘어나면 늘어날수록 연산이 많아져서 더 힘틀텐데 왜 그런말이 나왔는지 궁금하다. 단순히 데이터가 많으면 좋은건지, 아니면 조금 적더라도 양질의 데이터가 중요한지 문득 궁금했다.
'공부 > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| [밑시딥2] Chapter 6. 게이트가 추가된 RNN (0) | 2024.07.29 |
|---|---|
| [밑시딥2] Chapter 5. 순환 신경망(RNN) (1) | 2024.07.23 |
| [밑시딥2] Chapter 3. word2vec (0) | 2024.07.08 |
| [밑시딥2] Chapter 2. 자연어와 단어의 분산 표현 (1) | 2024.07.01 |
| [밑시딥2] Chapter 1. 신경망 복습 (1) | 2024.07.01 |