💅 SQL 입문
지난 시간에는 INSERT, DELETE, UPDATE를 통해 데이터를 검색뿐만 아니라, 추가, 삭제, 수정에 대해서 알아보았다. 이번 시간에는 SUBQUERY라는 개념에 대해서 학습하고 어떠한 상황에서 무슨 목적으로 사용하는지 알아보는 시간을 가져보도록 한다.
⛷️ SUBQUERY(서브쿼리, 하위쿼리)
서브쿼리를 한 줄로 요약한다면 "하나의 SQL문에 포함되어 있는 또 다른 SQL문"을 뜻한다. 정의로만 설명을 들으면 무슨 말인지 어렵기때문에 간단한 예시를 통해 서브쿼리에 대해서 알아가보도록 하자.
⛷️ WHERE 절에서의 SUBQUERY 활용
간단한 예를 들어보자. "연봉이 역대급으로 가장 높은 선수의 정보"를 출력한다고 가정하자. 지금까지 학습한 내용을 토대로 해당 선수의 정보를 출력하기 위해서는
1) salaries 테이블에서 연봉이 가장 높은 사람의 ID를 추출하고,
2) players 테이블에서 WHERE절에 playerID='추출한 ID'로 쿼리를 만든다.
와 같은 과정이 필요할 것이다.
-- 1) 연봉이 역대급으로 높은 선수의 정보
Select TOP 1 *
from salaries
ORDER BY salary DESC;

결과값을 살펴보면 'rodrial01'이라는 ID를 가진 선수가 연봉을 가장 많이 받는 것을 볼 수 있다.
--2) players테이블에서 rodrial01이라는 사람의 정보를 조회하자.
SELECT *
FROM players
WHERE playerID = 'rodrial01'

두 번의 쿼리 실행으로 우리가 찾고자 하는 정보를 조회하였다. 참으로 까다롭다. 1) 과정에서 찾은 ID를 바탕으로 별도의 하드코딩하는 과정이 있기 때문이다. 이러한 상황에서 서브쿼리를 이용해주면 된다.
--플레이어 정보를 조회할건데, 플레이어 아이디가
--(연봉 기준 내림차순 정렬시, 가장 1등인 사람)인 정보를 조회하자.
SELECT *
FROM players
WHERE playerID = (SELECT TOP 1 playerID from salaries ORDER BY salary DESC);
이와 같이 서브쿼리는 대부분의 상황에서 WHERE절에 활용한다. 해당 쿼리문은 단일행 서브쿼리인데, 한 사람(가장 높은 연봉)의 정보만 반환하기 때문이다. 만약 그렇다면, 1등부터 20등까지의 단일 행의 정보가 아닌 다중 행의 값을 추출하고 싶다면 어떻게 할까?
SELECT *
FROM players
WHERE playerID = (SELECT TOP 20 playerID from salaries ORDER BY salary DESC);
당연히 단일행에 다중값을 넣으려니 하니 오류가 뜨는 것을 볼 수 있다. 따라서 다중행을 위해선 =(equal) 대신 IN 키워드를 사용하면 된다. IN의 좋은 점은 중복된 행을 제거해준다는 점이다.
--실제론 20행이 아닌 9행만 나온다.
SELECT *
FROM players
WHERE playerID IN (SELECT TOP 20 playerID from salaries ORDER BY salary DESC);
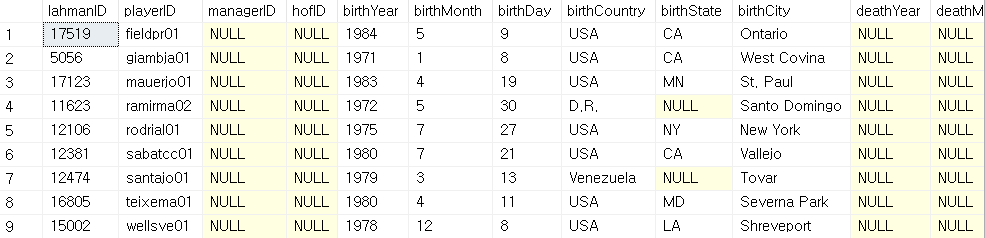
20개의 행이 아닌 9개의 행이 나온 이유는 해당 테이블에서 같은 플레이어 ID를 가졌음에도 년도별로 다른 연봉을 갖는 행 또한 존재하기 때문에 중복 제가 되어 9개가 나타난다.
⛷️ SELECT 절에서의 SUBQUERY 활용
서브 쿼리는 WHERE 절 뿐만 아니라 SELECT 절에서도 활용 가능하다. players 테이블과 batting 테이블의 행 개수를 저장하여 별도의 변수명으로 표기하고 싶다고 가정하자.
--players 테이블의 행 수를 playerCount, batting 테이블의 행 수를 battingCount로 저장하자.
SELECT (SELECT COUNT(*) FROM players) AS playerCount, (SELECT COUNT(*) FROM batting) AS battingCount;

아주 잘 나오는 것을 볼 수 있다. 😎
⛷️ INSERT 절에서의 SUBQUERY 활용
서브쿼리의 장점은 다양한 절에서 사용이 가능하다는 점이다. 이러한 장점은 INSERT 절에서도 활용 가능하다. 지난시간, 우리는 INSERT INTO문을 통해 일일이 열에 해당하는 값을 넣어줌으로써 새로운 행을 추가하였다. 그러나 만약 INSERT INTO 문 내 SELECT 문으로 가장 높은 연봉을 선택하여 열 값에 넣어줄 수는 없을까?
--가장 높은 연봉 값을 select로 조회하여 행을 삽입한다.
INSERT INTO salaries
VALUES (2020,'KOR','NL','rookiss5',(SELECT MAX(salary) FROM salaries))

또한 비슷하면서 같은 방법으로, VALUES를 사용하는 대신 아예 SELECT문으로 대체하는 방법도 있다.
--INSERT INTO VALUES와 똑같이 작동된다.
INSERT INTO salaries
SELECT 2020, 'KOR', 'NL', 'Rookiss6', (SELECT MAX(salary) FROM salaries)
그렇다면, INSERT INTO VALUES와 INSERT INTO SELECT의 차이점은 무엇일까? 결론부터 말하자면, INSERT INTO SELECT는 SELECT 문이므로, INSERT INTO VALUES와 다르게 한 행이 아닌 여러 행을 지정할 수 있다는 점이다.
예를 들면, 새 테이블에 기존 테이블 값을 복사하여 삽입할 경우 INSERT INTO VALUES는 일일이 한 행씩 넣어주는 작업을 해야 하는 반면, INSERT INTO SELECT는 SELECT 문 절로 '한번에' 모든 행을 집어넣을 수 있을 것이다.
⛷️ 상관관계 SUBQUERY
지금까지 단일 행, 다중 행에 관한 서브쿼리에 대해서 살펴보았는데, C#에서 사용할 수 있는 리스트 FindAll과 비슷한 개념인 EXISTS, NONEXISTS 개념도 존재한다. 처음 살펴보면 다소 난해한 정보이나 이러한 개념이 있다. 정도로만 알고 넘어가자.

포스트 시즌에 참여한 선수들의 목록을 SELECT 문을 이용하여 추출해보자.
--battingpost 내 playerID가 players 내 playerID에 있는가?
SELECT *
FROM players
WHERE playerID IN(
SELECT playerID FROM battingpost);
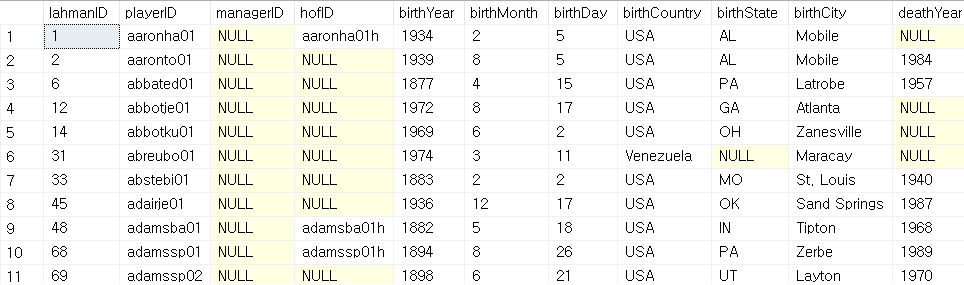
포스트 시즌에 참여한 선수들의 목록은 players 테이블에 있는 playerID가 battingpost 테이블에도 있다는 의미이다. 마찬가지로 다중 행이므로 역시 IN 키워드를 이용하였다. 이와 같은 의미의 EXISTS는 다음과 같다.
--'선수들' 목록이니, players 테이블에서 행을 선택한다.(select *문)
--battingpost 테이블 내 playerID가 players 테이블 내 playerID와 같은게 존재하는가?
--존재한다면, 포스트 시즌에 참여한 선수다.
--없다면, 포스트 시즌에 참여하지 않은 선수다.
SELECT *
FROM players
WHERE EXISTS(SELECT playerID FROM battingpost WHERE players.PlayerID=battingpost.playerID);
이렇게 WHERE과 EXISTS를 함께 사용할 경우 IN 보다 더 넓은 범위에서 정보를 가져올 수 있다. IN 같은 경우에는 조건 안에 있는 애들중에서 무엇무엇을 해라의 의미가 되지만, WHERE은 단순 식으로 비교도 할 수 있고, 값을 넣어서 조건을 추가 하는 등 IN 보다 확장성이 넓은 다재다능 한 비교가 되기 때문이다.
'공부 > 인프런 - Rookiss' 카테고리의 다른 글
| Part 5-2-13. SQL 입문 : 정규화 (1) | 2024.02.13 |
|---|---|
| Part 5-2-12. SQL 입문 : 데이터베이스 작성 (0) | 2024.02.13 |
| Part 5-2-10. SQL 입문 : INSERT, DELETE, UPDATE (1) | 2024.02.12 |
| Part 5-2-9. SQL 입문 : GROUP BY (0) | 2024.02.12 |
| Part 5-2-8. SQL 입문 : 연습문제 (0) | 2024.02.08 |