🌚 부록
지난 시간에는 데이터베이스 원리에 대해서 알아보았다. 데이터베이스는 많이, 빠르고, 안전하게 이 3가지의 특징을 잘 지켜야 하는데 각각의 개념은 서로 상충되기 때문에 쉽게 이 모든 것을 지키며 수행하기가 어렵다는 것을 알 수 있었다. 그렇지만 그 중에서도 안전성은 정말 정말 중요했기 때문에 무조건적으로 지켜야 한다는 것 까지 알 수 있었다. 오늘은 더 나아가 쓰레드와 캐시에 대해서 알아보는 시간을 가지되 이전 시간과 마찬가지로 실습이 아닌 이론을 통해 알아보도록 한다.
⚽ 쓰레드
사실 쓰레드와 캐시는 Part 4 게임 서버 수업에서 이미 학습한 경험이 있어서 크게 어렵지 않다. 쓰레드와 캐시가 꼭 게임 서버에 국한되는 것이 아니라, SQL에도 적용되는 것이다. 그렇다면 데이터베이스에서 쓰레드와 캐시는 어떻게 사용되는지 먼저 알아보도록 하자.

지난 시간과 같이 데이터베이스를 물류창고라고 비유하여 알아보도록 하자. 데이터베이스에서 실질적으로 작업하는 내용은 크게 2가지로 나뉜다. 1. Read, 2. Write 이다. 먼저 알아볼 것은 Read이다. 데이터베이스에서 Read가 실질적으로 어떻게 이루어지는지 확인해보도록 하자.

파란색으로 그려져 있는 친구는 데이터베이스에서 근무하는 직원이고, 노란색으로 그려져 있는 친구는 정확히 따지면 게임 서버의 역할을 하는 데이터베이스 클라이언트다. 프로세스를 살펴보면 먼저 1번에서 SQL 쿼리를 날릴 경우, 직원은 이를 파싱해서 물류창고에서 데이터를 가져오고, 4번 결과와 같이 값을 반환하여 클라에게 다시 결과를 돌려준다.

반대로 Write를 하는 경우, 이번에도 시작은 클라이언트에서 요청을 할 것이다. 예를들어 인서트, 업데이트 같은 SQL 문을 요청하면 직원은 이를 파싱하고 알맞은 곳에 데이터를 갱신 후 성공할 경우 결과 값을 반환하는 형태로 진행 될 것이다. 하지만 데이터베이스가 이렇게 순진하게 동작하진 않는다.
왜냐하면 이렇게 동작할 경우 데이터베이스의 주요 특징 중 하나인 많이, 빠르게, 안전하게 중 빠르게를 만족하지 못하기 때문이다. 그렇다면 이를 어떻게 처리할 수 있을까? 벌써부터 '저장하는 영역과, 안내하는 영역을 나누면 되지 않을까?' 생각이 든다. 그래서 이전에 게임 서버에서 배웠던 것과 마찬가지로 데이터를 저장하는 친구 한명, 호텔 프론트와 같이 결과값의 반환만 안내 하는 친구 한명을 두어 처리할 수 있을 것이다.

위와 같이 나눠줄 경우 이미지에서 영업 전문 직원은 요청을 받으면 Ok 사인만 넘겨주고, 실질적으로 데이터의 갱신은 뒤처리/운영 전문 직원이 처리하는 것이다. 이는 결국 데이터베이스도 멀티쓰레드 방식으로 돌아가야 된다는 의미이다. 이렇게해서 데이터베이스의 쓰레드에 대해서 알아보았다.
⚽ 캐시
위와 같이 데이터베이스에서 사용하는 쓰레드에 알아보았다. 이제 캐시에 대해서 알아보도록 하자.

아까와 같이 영역을 나눠서 동작을 처리하는 것은 굉장히 바람직함에도 불구하고 근본적으로 해결되지 않는 내용은 바로 '데이터를 쓰는 작업 자체가 오래 걸리는 것'은 변함이 없다. 따라서 Write 하는 경우, 위에서 배운 것과 마찬가지로 백그라운드 직원에게 떠넘기고 결과만 Ok로 뻥치면 되었지만, Read는 그렇지 않다는 것을 알 수 있다. 따라서 우리가 백그라운드 직원에게 업무를 시킨다고해도 결국 이 데이터를 진짜 가져오기 전까지 우리는 결과를 반환해 줄 수 없다. 그러면 매 번 이렇게 오래걸릴 순 없는법. 어떻게 처리해야 할까?
바로 여기서 '캐시'라는 개념이 등장한다. 데이터베이스의 캐시의 개념은 우리가 호텔 프론트에 짐을 맡길 경우, 이 짐을 3층과 같은 공간에 보관하는 것이 아닌, 프론트 뒤의 작은 창고가 있는데 거기에데가 모든 짐을 보관하는 것이라고 생각하면 된다. 그러면 이 내용이 Read와 무슨 상관이 있을까?

바로 데이터를 찾기 위해 물류창고까지 가지 않고 프론트에서 임시 창고를 확인 한 뒤, 해당 데이터가 있을 경우 창고에서 바로 찾아서 꺼내줄 수 있는 것이다.
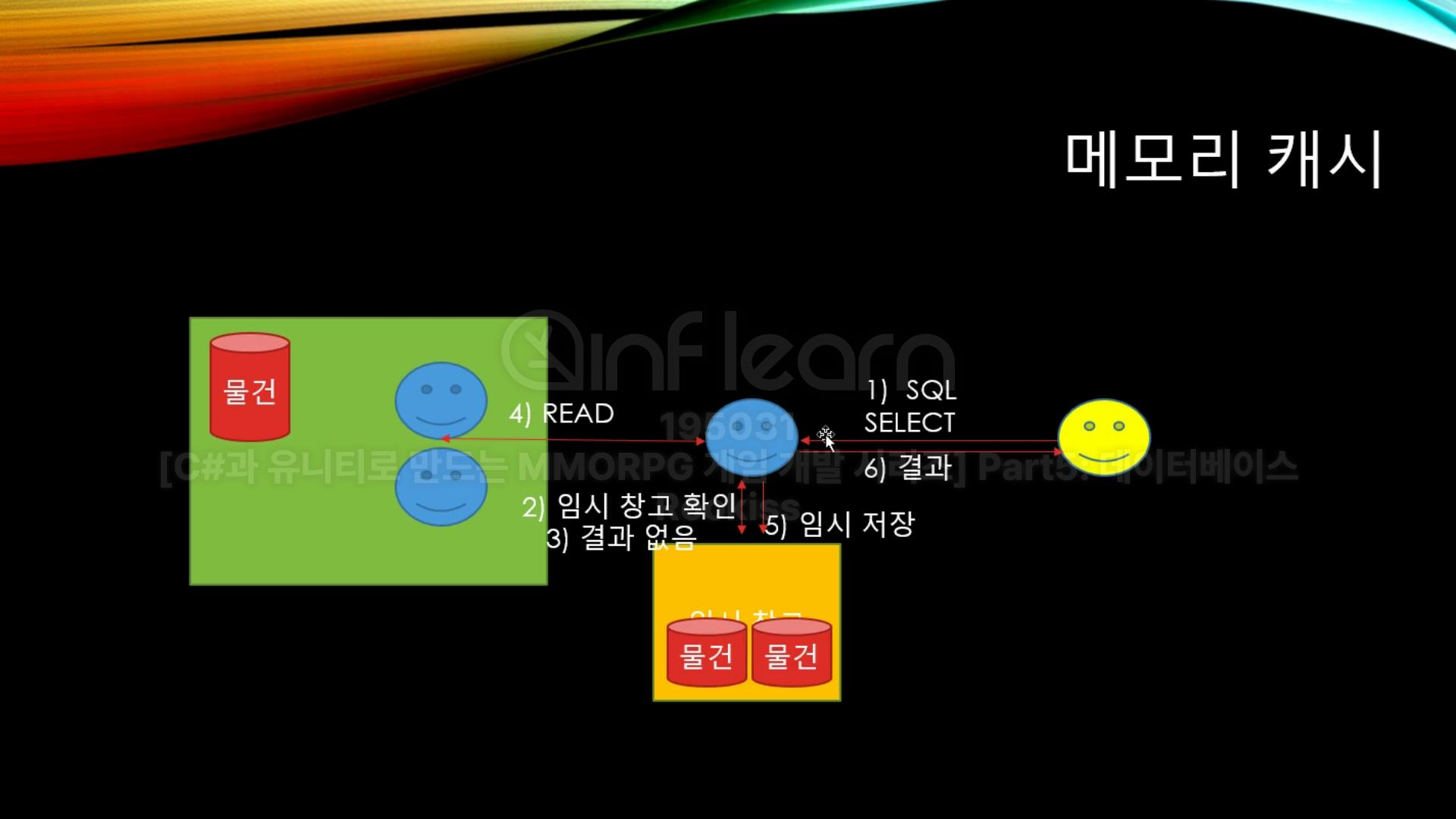
그렇지만 임시 창고에 우리가 원하는 데이터가 없을 경우, 어쩔 수 없이 뒤에서 일하는 직원에게 데이터를 찾아오라고 일을 시켜 찾아와야 한다. 그렇다면 추가적으로 우리가 자주 사용하는 인덱스는 어디에 저장되어 있을까? 이는 아래와 같다.

우리가 물류 창고에서 물건을 찾는 것과 같이 동일하게, 인덱스도 '인덱스'로 분류를 두어 따로 물류창고에 저장되고 있다. 따라서 클라이언트가 인덱스를 통해 데이터를 조회했는 데 그 값이 임시 창고에 있을 경우 임시 창고에 있는 인덱스를 활용 하여 조회를 시작하고, 그렇지 않을 경우 마찬가지로 뒤에서 일하는 직원을 시킨다.
그렇다면 마지막으로 임시 창고가 꽉 찰 경우 어떻게 해야할까?

사실 이 문제는 데이터베이스 뿐만 아니라 캐시를 사용하는 모든 프로그램에 나타나는 공통적인 문제이기도 하다. 캐시는 내가 사용한 정보가 또 활용 될 수 있으니 저장해두었다가 다시 사용하는 것인데 이 또한 시간이 흘러 캐시에 기록한 것이 점점 많아질 경우 공간이 부족하게 된다. 따라서 캐시는 주기적으로 정리를 하게 되는 데 이 때 사용하는 알고리즘이 정보처리기사 때에도 배웠던 LRU 기법이다. 해당 기법은 최근 활용도가 적엇던 캐시 위주로 정리를 하는 것이다.
⚽ 오늘의 결론
결국 데이터베이스는 우리가 데이터를 요청한다고 해서 항상 하드 디스크까지 접근을 하지 않는다는 것이 핵심이다. 또한 캐시를 활용하기 때문에 처음 데이터 조회 할 경우와 두 번째로 데이터를 조회 할 경우 속도의 차이가 날 수 있다. 그리고, 데이터베이스 시스템이라고 해서 '마법'과 같은 프로그램은 아니고 결국 어떤식으로든 컴퓨터 기능을 활용해서 돌아가는 프로그램에 불과하다는 것임을 명심하자.
'공부 > 인프런 - Rookiss' 카테고리의 다른 글
| Part 5-4-4. 부록 : 트랜잭션 (3) | 2024.07.22 |
|---|---|
| Part 5-4-3. 부록 : 대기와 락 (1) | 2024.07.20 |
| Part 5-4-1. 부록 : 데이터베이스 원리 (1) | 2024.07.19 |
| Part 5-3-10. SQL 튜닝 : Sorting (1) | 2024.07.18 |
| Part 5-3-9. SQL 튜닝 : Hash 조인 (0) | 2024.07.17 |